




Content Chunking: Is Your Content Built for AI Search?

In the not-so-early days of the web, “long-form” content was often equated with authority. The common belief was simple: more words meant more expertise. However, as digital consumption habits have matured, the “wall of text” has become a significant barrier to engagement rather than a sign of quality. In 2026, the shift toward modular information reflects a structural necessity as well as an aesthetic evolution.
As AI agents and LLMs move from indexing pages to extracting specific passages, the way we organize data is becoming increasingly important. To remain accessible to both human readers and search algorithms, utilizing content chunking is a helpful practice.
What is content chunking?
At its core, content chunking is the process of breaking down large blocks of information into smaller, self-contained units or “chunks.”
Here is an example of what I mean by “chunks”, compared to non-chunked content:

Think of it like a Lego set. Instead of one solid, immovable block of data, your content becomes a series of individual pieces that can be easily processed, rearranged, and understood. In a digital context, this involves several key formatting and structural choices:
- Short paragraphs: Limiting ideas to 3–4 sentences to keep the reader’s attention focused.
- Meaningful subheadings: Acting as descriptive “labels” for the information below, allowing for easy navigation.
- Lists and callouts: Pulling key data or actionable steps out of the narrative flow to make them “pop.”
- White space: Giving the reader’s eyes a place to rest, which prevents cognitive fatigue.
By chunking content into digestible bites, you reduce the “cognitive load” on the reader and help AI systems process information more efficiently. Instead of forcing a human brain (or an algorithm) to work hard to filter out the main point from a dense paragraph, you serve that point directly.
New strategy or old best practice?
I find it somewhat frustrating to see content chunking framed as a “new” trend or a secret AI tactic. Experienced creators have been doing this all along, often under the simpler label of “good writing”.
The reality is that “chunking” is a modern name for a very old set of web best practices. For decades, SEOs and UX designers have advocated for hierarchical headings (H1-H6) to guide the reader’s eye and writing for the F-Pattern, the way humans naturally scan web pages.
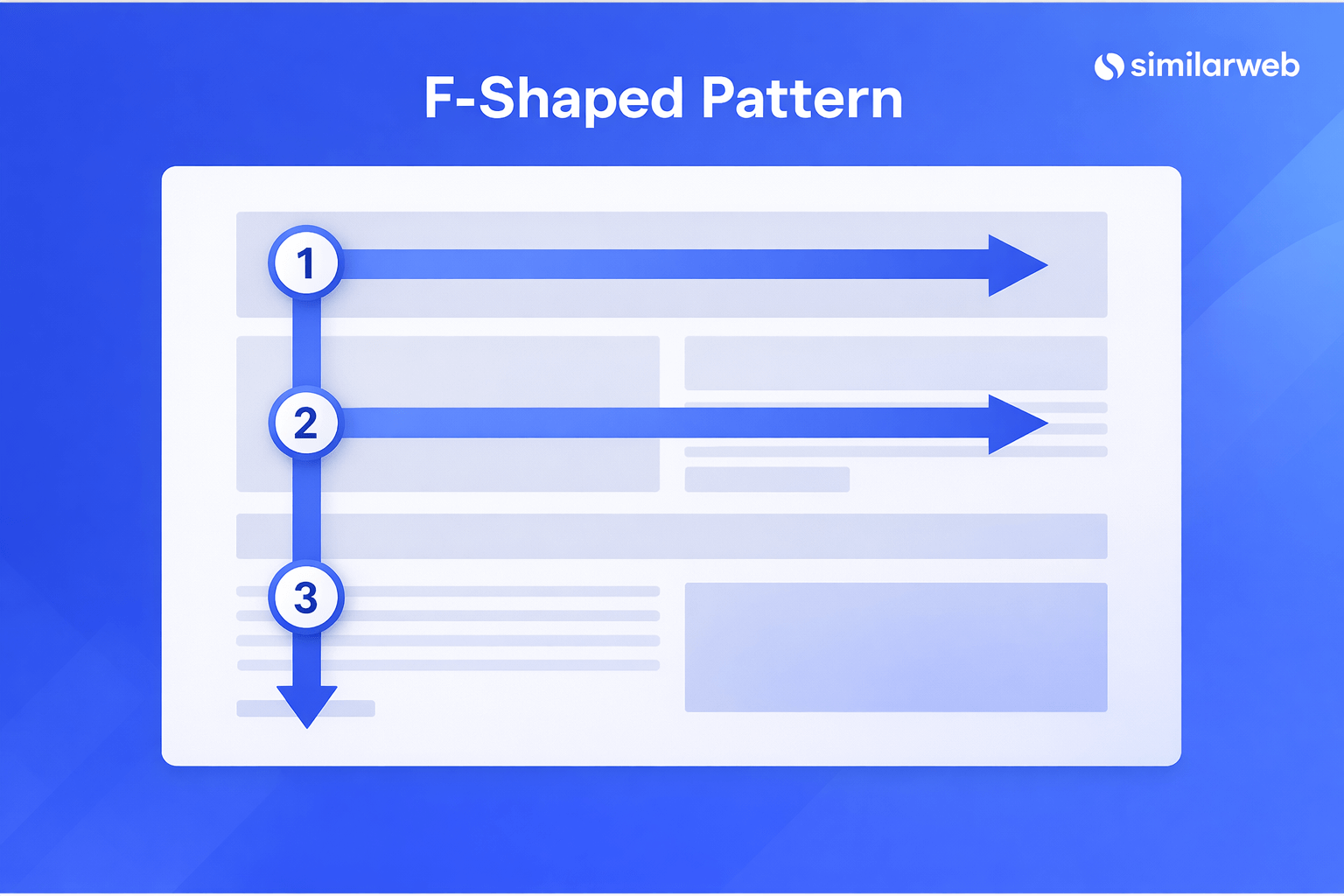
What has changed is how these practices are being utilized. While search engines have used H tags in their algorithms for a long time to understand content hierarchy, these markers have now also become primary signals used by AI chatbots and LLMs to parse, summarize, and cite information. We aren’t reinventing the wheel; we are simply recognizing that the same “wheel” that helped humans skim and search engines rank is now the engine that helps AI “understand” and retrieve data with higher precision.
Why I agree with Google: Structure vs. fragmentation
While I’m a big believer in structure, I think there’s a danger in over-optimization.
In early 2026, Google’s Danny Sullivan addressed this directly on the Search Off the Record podcast. As reported by Search Engine Roundtable, he warned publishers against turning content into “bite-sized chunks” purely to rank well in LLMs or AI Search.
The goal should always be structure for clarity, not fragmentation for machines. If a page is divided in a way that feels unnatural to a person, it is likely over-optimized and may eventually be penalized by search systems designed to reward natural, high-quality information.
The science of “Digestible Bites” and AI retrieval
The effectiveness of chunking is rooted in Cognitive Load Theory, but it is also validated by modern AI behavior.
Research into visual scanning patterns, such as the F-Pattern and the Layer Cake pattern, shows that human readers look for “hooks”, bold text and headings, to decide if a section is worth reading.
AI retrieval follows a similar technical logic. Modern AI systems use semantic chunking strategies to break documents into vector embeddings. This process is the backbone of Retrieval-Augmented Generation (RAG), where an AI “retrieves” a specific chunk of your content to “generate” an accurate answer. When content is structured into distinct, self-contained sections, it is easier for these models to match a specific “chunk” of text to a user’s query. By organizing information into these units, you are essentially providing the AI with ready-made answers that are easier to retrieve and cite.
What I’ve learned gets cited
I’ve realized it’s a mistake to think that chunking alone is the “secret sauce.” Chunking helps AI find the info, but the substance is what gets it cited. In my work, I focus on four things:
- Original Research: I try to share data from my own internal studies because AI loves verifiable facts.
- Anticipating Follow-ups: I look for “fan-out” queries, the questions a reader might ask after my main point, and I answer those, too.
- Freshness: I make sure my best practices are up-to-date.
- The Direct Answer: I try to use an “Inverted Pyramid” style, putting the direct answer in the very first sentence under a heading.
Practical checklist: How to properly chunk your content
This is the checklist I use to audit my own work for both UX and AI retrievability:
- Descriptive HTML Headings: Avoid vague headings like “Overview.” Instead of “Tips”, use “5 Strategies to Increase Open Rates.”
- The “Inverted Pyramid” Paragraph: Does the first sentence under the heading provide the direct answer?
- Self-Contained Paragraphs: Can each paragraph make sense if it were pulled out of the article individually? Minimize dependencies on “This” or “As mentioned above.”
- Hierarchical Lists: Are lists used for any sequence of three or more items to maximize scannability?
- The FAQ Advantage: Have you included a dedicated Q&A section to leverage the highest-performing retrieval format?
Measuring visibility with Similarweb’s AI tools
To turn these theories into a measurable strategy, I need to see how AI is actually treating my site and my competition. I rely on Similarweb’s AI Brand Visibility tool to bridge the gap between “good writing” and “verifiable visibility.”
Analyzing the “Why” with Citation Analysis
I use the Citation Analysis tool to see exactly which sources are shaping AI answers for my industry. It’s about seeing my own domain as well as understanding the influence score of different URLs.
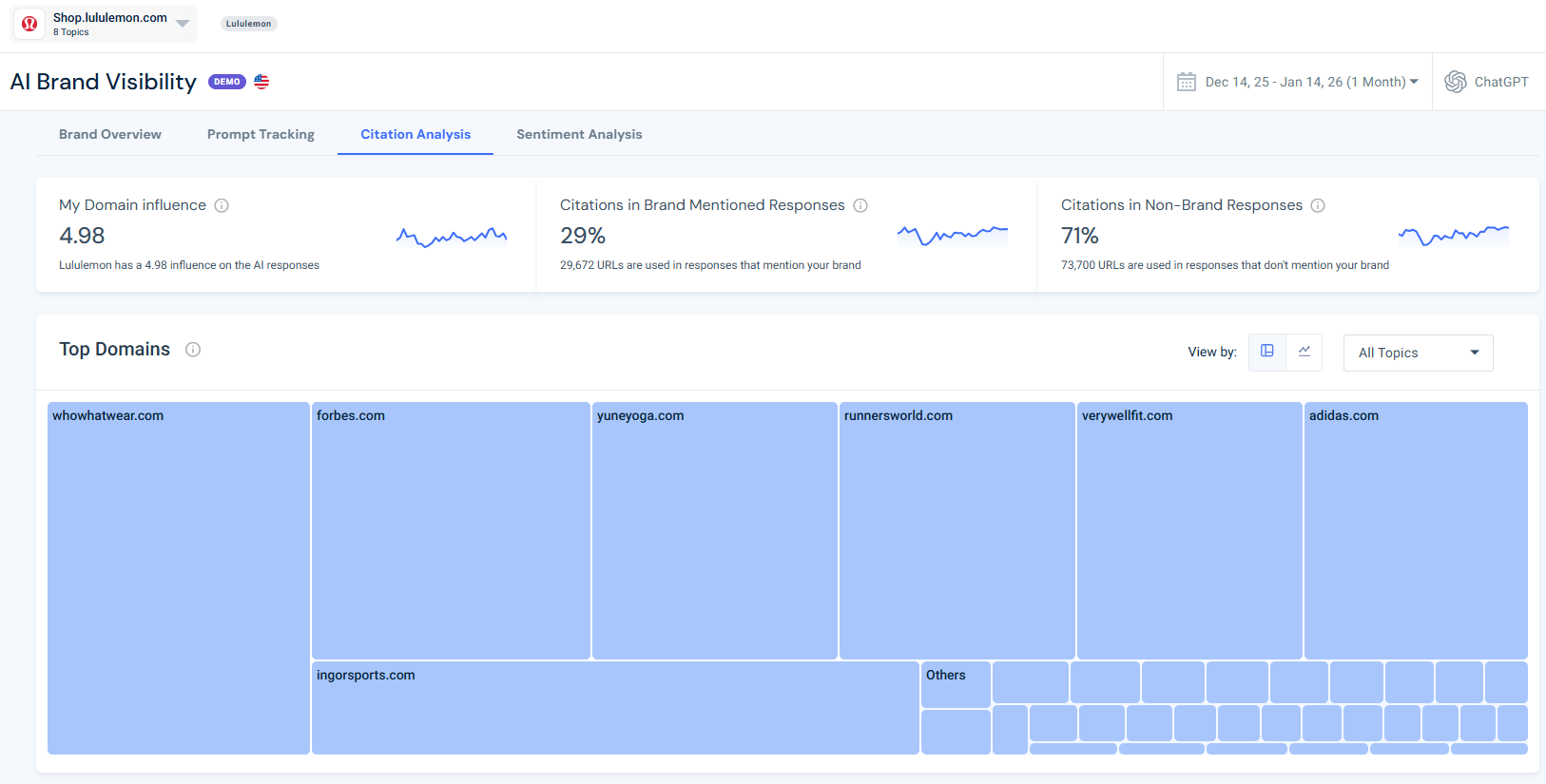
- Identifying Influencers: I look at “Top Domains by Topic” to see which publishers or review sites ChatGPT trusts most for my niche.
- Reverse-Engineering Success: If a competitor’s URL has a high Influence Score, I drill down to the exact page. I analyze how they chunked that content and whether they use better headings.
- Spotting Gaps: I check if my own brand is cited under the “My Domain” category. If I’m missing, I know I need to bolster my content structure on the URLs identified as “weak.”
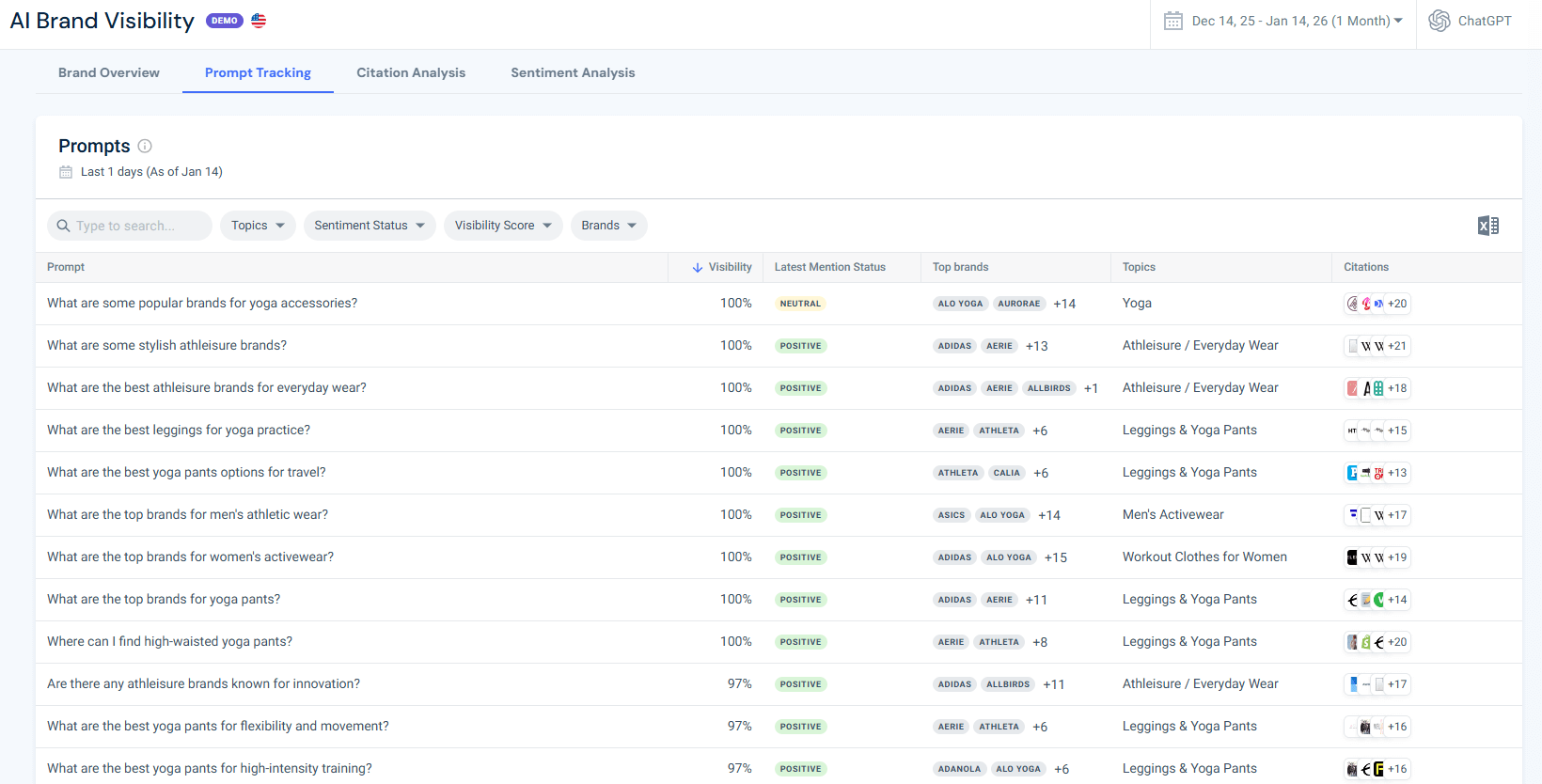
Understanding the “How” with Prompt Analysis
I use the Prompt Analysis tool to see the actual questions users are asking ChatGPT within my tracked topics. This is where the strategy gets practical:
- Identifying Missing Mentions: If my brand is missing from an answer to a relevant prompt, I review the citations the chatbot relied on.
- Tailoring Content Strategy: I use these prompts to guide my headings and FAQ section. If people are asking about “pricing for X,” I make sure I have a self-contained “chunk” that answers that specific question directly.
Future-proofing your strategy
To me, content chunking is the bridge between human readability and AI retrievability. While the terminology might keep changing, from UX to AEO to RAG, my core mission remains the same: making information accessible, and then Google rankings and visibility on AI will follow.
I believe the most successful creators will be those who provide high-quality substance in a modular, human-centric format. Structure is just as important as substance, but I will never sacrifice the human experience for an algorithm.
Ready to see how your brand stacks up? Get started with a free trial of Similarweb’s Web Intelligence platform today to monitor your AI visibility and stay ahead of the competition.
FAQs
Should I rewrite my high-performing old articles into chunks?
I wouldn’t do a mass rewrite. Instead, I use a tool like Similarweb to see which of my top pages are losing visibility in AI answers. Those are the ones I update. I start by adding an FAQ block at the bottom and breaking up the densest paragraphs.
Can I over-chunk my content?
Yes. If every single sentence is its own paragraph or a bullet point, you lose the narrative flow and the “glue” that holds your expertise together. I make sure my chunks still follow a logical sequence so that a reader, or an AI, understands the relationship between the different parts.
How long should a “chunk” be in terms of character count?
While there is no hard rule, AI engineers often find that chunks between 300 and 500 words work best for retrieval. However, from my perspective, you shouldn’t write to a character count. Write until the specific idea or answer is complete. If it’s too long, add a subheading to create a new semantic boundary.

Related Posts


Why AI Engines Cite UGC Over Brand Content And How To Leverage It For AEO

AI Mentions vs. AI Citations: What’s the Difference and Why It Matters for GEO


How to Do A Competitive Analysis: Complete Guide & Free Templates


Wondering what Similarweb can do for your business?
Give it a try or talk to our insights team — don’t worry, it’s free!