




The 10 Biggest GEO Mistakes That Keep You Invisible to AI (+ One You May Be Doing Without Knowing)

We are living through the single biggest shift in search behavior since the introduction of the index. For more than twenty years, our job was to convince an algorithm to rank us in a list of ten blue links. In 2026, we are convincing a reasoning engine to cite us as the single source of truth.
Generative Engine Optimization (GEO) isn’t just “SEO with more content.” It is a fundamental strategy for how we present information to machines that read, reason, and summarize.
I talk to SEOs every day, and many of them are struggling to adapt. Most are simply applying old-school tactics to new-school engines, only to have them backfire.
After analyzing thousands of AI-generated responses and the underlying data structures that power them (using AI), I’ve identified the critical mistakes causing brands to vanish from the AI conversation.
Here is how you might be failing at GEO, and exactly how to fix it.
1. Ignoring entities (The “keyword stuffing” hangover)
The Mistake:
You are still writing for a keyword frequency algorithm, stuffing your H2s with exact-match phrases, hoping to trigger a ranking signal.
The Reality:
LLMs (Large Language Models) do not rely on keyword density. They rely on Semantic Proximity and Entity Relationships. They don’t look for the string “best enterprise CRM” repeated five times, but look for the concept of CRM software and its connection to related entities (like “Salesforce,” “lead scoring,” “pipeline management,” and “API integration”).
If you write “The best CRM software is a software that helps with CRM,” you might satisfy a 2010 search bot. But to an LLM, that sentence has zero information gain. It views it as “fluff” or “noise” and will statistically downweight it in favor of a source that provides concrete relationships.
The Fix:
- Optimize for “Information Density”: Stop explaining the obvious. Focus on unique data points, proprietary statistics (like our Gen-AI landscape report), and clear definitions.
- Build Knowledge Graphs: Ensure your content connects the dots. If you mention a product, immediately mention its parent company, its price point, and its primary use case in close proximity.
- Use Similarweb: Use the Keyword research tool, but filter for Questions specifically. These question clusters often reveal the semantic gaps (or missing entities) your content needs to fill to be “cite-worthy.”
2. Neglecting “token efficiency” (Marketing fluff)
The Mistake:
Your content is filled with “corporate speak”. Words like “revolutionary,” “cutting-edge,” and “best-in-class” without data to back them up.
The Reality:
LLMs have a “context window” (a limit on the amount of text they process) and a “token budget.” They are trained to predict the next likely word based on probability.
High-adjective, low-fact sentences lower the model’s “confidence score.” (OpenAI’s own engineering guidelines explicitly warn that reducing ‘fluff’ is critical for model accuracy)
When an AI reads “We are the world’s leading solution,” it treats this as a low-probability hallucination risk unless backed by a citation.
The Fix:
- Adopt “The Inverted Pyramid” for AI (classic AEO): Start every section with a direct, factual answer (approx. 40-60 words). This is “citation bait.”
- Remove Subjective Adjectives: Replace “We offer a fast implementation” with “Implementation takes 4 hours.”
- Think in Tokens: Don’t waste the AI’s processing budget on intro fluff (“In today’s fast-paced digital world…”). Get straight to the syntax the LLM prefers: Subject + Verb + Object + Fact.
3. The “unstructured” data mess
The Mistake:
You are publishing great content, but it’s buried in long, dense paragraphs.
The Reality:
LLMs love structure. In fact, research from Princeton and Adobe found that modifying content to include citations and quotations can improve Generative Engine visibility by up to 40%.
LLMs are mathematical models that digest patterns. A paragraph of text is harder for an LLM to parse and extract “facts” from than a table, a list, or structured JSON-LD.
If your pricing is hidden in a sentence (“It costs $10 for basic and $20 for pro…”), the AI might miss it. If it’s in a table, the AI can easily grab that row and serve it to the user.
Real-life example of an unstructured data mess:
Check out Zoominfo’s pricing page. It is “gated” (buried behind a “Contact Sales” form and a “View Pricing” button) and unstructured.
Now, search Google or Perplexity for “How much does ZoomInfo cost?”
What happens? The AI does not cite ZoomInfo. Instead, it cites G2, or GetApp.
Why? Because those aggregators present the estimated pricing in a clear HTML Table or structured list ($14,995/year). The AI “scrapes” the fact from the third party because the official source refused to structure the data for the machine. ZoomInfo loses the “Source of Truth” status for its own product’s price.
The Fix:
- Markdown is King: Write your content with clear hierarchy (H2, H3) and use bullet points liberally.
- Tables for Comparisons: Always use HTML tables for “vs” content (e.g., “Competitor A vs. Competitor B”). LLMs are highly trained to scrape and reproduce table data.
- Schema Markup: Go beyond basic Article schema. Use the FAQPage, Dataset, and TechArticle schema to explicitly help the model classify exactly what the data is.
4. Measuring clicks instead of citations
The Mistake:
You are looking at your traditional web analytics and panicking because organic traffic is flat, even though you are optimizing for AI.
The Reality:
GEO is often a Zero-Click (or Zero-Visit) game. If Perplexity answers a user’s question about your product perfectly, they may never visit your site.
This sounds bad, but the alternative is worse: Perplexity answering the question using your competitor’s data because you refused to play.
Brand Visibility (AI Share of Voice) is the new click. You want to be the source the AI cites, establishing your brand as the authority.
The Fix:
- Shift KPIs: Move from “Traffic” to “Share of Voice.”
- Use Similarweb’s AI Search Intelligence Suite: This is critical. You cannot optimize what you cannot measure.
- AI Brand Visibility tool: Check how often your brand appears in AI-generated answers compared to competitors.
- AI Traffic Tracker: Monitor the specific referral traffic coming from chatgpt.com, bing.com (Copilot), and perplexity.ai. This traffic is often lower volume but significantly higher intent.
- AI Citation Analytics: Use this to see which external sources the AI is citing when it talks about your industry. If the AI loves citing a specific industry report or news site, you need to get coverage on that site.
5. Inconsistent “entity home” (The trust gap)
The Mistake:
Your FAQ page says “30 days,” your About page says “14 days,” and a third-party review site says “No returns.”
The Reality:
When an LLM encounters conflicting facts about an entity (your brand), it “hallucinates” or, more likely, defaults to the most authoritative source it can find (which might be Wikipedia rather than your site).
If you don’t have a single, consistent “Entity Home” (a canonical source of truth), you confuse the model.
The Fix:
- Audit Your Digital Footprint: Ensure your N-A-P (Name, Address, Phone) and core business facts (pricing, founder, founding year) are identical across your site, LinkedIn, Crunchbase, and social profiles.
- The “About Us” Page: Turn this into your “Entity Home.” Pack it with schema markup that defines exactly who you are, what you do, and your corporate hierarchy.
Real-life example of inconsistent entity representation:
When Elon Musk rebranded Twitter to “X,” the domain changed, but millions of third-party profiles (LinkedIn, Crunchbase, App Store descriptions) still said “Twitter.”
For months, generative engines were hallucinating. If you asked, “What is the support email for X?”, early versions of AI models would hallucinate emails for unrelated companies named “X” or say “I don’t know,” because the Entity Relationship between “X” and “Social Media Platform” wasn’t solidified in the Knowledge Graph.
It took massive, consistent updates across N-A-P (Name, Address, Profile) data on external authority sites (Wikipedia, Bloomberg, App Stores) to “teach” the AI that X = Twitter.
6. Blocking the bots (Technical suicide)
The Mistake:
You are so worried about your content being “stolen” by AI that you block GPTBot, CCBot, or Google-Extended in your robots.txt.
The Reality:
If you block the bots, you opt out of the future of search. You are ensuring that when a user asks ChatGPT, “What is the best tool for X?”, your brand cannot be the answer. You are invisible.
Furthermore, relying heavily on client-side JavaScript (CSR) can hurt you. While Google is good at rendering JS, many AI crawlers (which are often less sophisticated than Googlebot) prefer raw HTML. If your content loads via JS, the AI might just see a blank page.
Real-life example of technical suicide:
Check out the NYT’s robots.txt file:

Now, Open ChatGPT or Claude AI and ask: “Summarize the latest analysis on the [Current News Topic].
The AI will often cite The Verge, CNN, or Politico as its sources. It cannot read the NYT’s analysis, so it ignores it. By blocking the bot, the NYT has effectively handed the “citation authority” for its own breaking news to secondary aggregators that allow bots in.
The Fix:
- Open the Gates: Allow AI bots in your robots.txt. The traffic they bring (and the brand awareness they generate) outweighs the risk of content scraping.
- Server-Side Rendering (SSR): Ensure your core content is delivered in the initial HTML response, not loaded dynamically.
7. The “grounding” gap (Fear of external links)
The Mistake:
You refuse to link to other sites because you don’t want to “leak authority.” You want users to stay on your page.
The Reality:
LLMs suffer from hallucinations. To fix this, engineers build “Grounding” mechanisms. The AI looks for consensus across multiple high-authority sources to verify a fact.
If your content makes a claim (e.g., “We are the fastest tool”) but does not cite external, neutral data (like a G2 report, a government study, or a major news outlet) to support it, the AI flags your content as “unverified marketing claims.”
The Fix:
- Cite to Rank: Ironically, linking out to high-authority sources increases your trust score with AI. It tells the model, “This data is grounded in the consensus reality.”
8. The “date drift” (Temporal ambiguity)
The Mistake:
You update a blog post’s content but don’t explicitly update the schema date, or you use vague language like “Currently” or “This year.”
The Reality:
LLMs have a “training cutoff.” When they browse the live web (RAG), they are desperate to know if information is current.
If an AI sees a price of $50 but can’t find a definitive “Last Updated: January 2026” timestamp in the code, it may discard the data in favor of an older source that is clearly dated, or it may hallucinate that the 2023 price is still valid.
The Fix:
- Explicit Date Stamping: Avoid relative time (“Last month”). Use absolute dates (“As of January 2026”).
- dateModified Schema: Ensure your structured data explicitly signals content freshness.
9. The “siloed” reputation (Ignoring co-occurrence)
The Mistake:
You only publish content on your own domain.
The Reality:
LLMs learn by association (vectors). If the words “Your Brand” and “Best Enterprise SEO Tool” effectively never appear together on other authoritative websites (Forbes, Search Engine Journal, Reddit discussions), the AI will not form a strong vector relationship between them.
You cannot “tell” the AI you are the best; the web must “convince” the AI you are a contender.
The Fix:
- Digital PR for Co-Occurrence: Your off-page strategy shouldn’t just be about “backlinks” for juice. It should be about Textual Co-occurrence. You want your brand name mentioned in the same paragraph as your target keywords on third-party sites.
10. The “persona” mismatch
The Mistake:
You write all content for a generic “user.”
The Reality:
AI searchers rarely use generic prompts. They use persona prompts: “Act as a CTO and tell me which software is best,” or “Act as a Junior Dev and explain this error.” If your content is too simple, you miss the CTO prompt. If it’s too dense, you miss the Junior Dev prompt.
The Fix:
- Multi-Tiered Content: In your long-form guides, include sections for different personas. “The Executive Summary (For CTOs)” vs. “The Technical Implementation (For Developers).” This allows the AI to grab the specific section that matches the user’s prompt persona.
🚨 11. The “one-shot” optimization fallacy (The hidden mistake)
This is the mistake virtually no one is talking about, yet it is responsible for the majority of lost conversion opportunities in AI search.
Most SEOs optimize for the First Query.
- User asks: “Best CRM for small business.”
- You optimize for: Appearing in that list.
The Mistake:
AI Search is Conversational. The user almost always asks a follow-up.
- User asks: “Which of those has the best API?”
- User asks: “Can you give me a comparison table of the pricing for the top 3?”
If you optimized your “Best CRM” page to just be a list of names, you win the first interaction but lose the conversion. The AI will pull data from your competitor to answer the follow-up question about APIs or pricing because you didn’t structure that data clearly.
The Fix:
Optimize for the “Contextual Chain.” Anticipate the next 3 questions a user will ask after they find you.
- Do you have a clear API documentation section linked or summarized on your product page?
- Is your pricing easy for an AI to turn into a table?
Similarweb Insight: Use the Keyword Generator to find long-tail “VS” and “Pricing” questions. These are often the “Follow-up” queries.
Ensure your content answers them on the same page or is properly linked, so the AI stays with your brand throughout the entire conversation.
Here’s a table summarizing the top mistakes and fixes:
| Feature | The Mistake | The Fix |
| Optimization Unit | Keywords & Frequency | Entities & Relationships |
| Content Style | Marketing “Fluff” & Jargon | Inverted Pyramid (Facts First) |
| Data Format | Unstructured Paragraphs | HTML Tables & Schema Markup |
| Success Metric | Organic Traffic (Clicks) | Share of Voice (Citations) |
| Bot Access | Blocking Bots (Disallow) | Open Access (Allow GPTBot) |
| Verification | Internal Claims Only | Grounding (External Citations) |
| User Journey | Single Query (The Click) | Contextual Chain (The Conversation) |
| Source of Truth | Inconsistent (Scattered) | Unified “Entity Home” |
✅ The GEO “Health check” (Downloadable checklist)
Understanding the theory behind Generative Engine Optimization is critical, but execution is what drives citations. To help you bridge the gap between strategy and action, I’ve consolidated these “pass/fail” signals into a practical audit tool.
Copy the full GEO checklist here
Use this checklist to score your high-value pages right now. If you can’t check at least 80% of these boxes, your content is at risk of being ignored by the reasoning engines that matter.
Phase 1: Technical & Access
- [ ] Robots.txt: Are GPTBot, CCBot, and Google-Extended allowed?
- [ ] Rendering: Is core content visible in raw HTML (not hidden behind JS)?
- [ ] Schema: Is Organization, FAQPage, and Article schemas validated?
- [ ] Date Stamping: Is dateModified schema active and accurate?
Phase 2: Content Structure (The “Reasoning” Layer)
- [ ] The Inverted Pyramid: Does the H1/intro answer the core question in <60 words?
- [ ] Formatting: Are comparisons using HTML Tables (<table>)?
- [ ] Lists: Are features/steps formatted as Bullet Points (<ul> / <ol>)?
- [ ] Grounding: Are specific statistics cited to external authorities?
Phase 3: Brand Authority (The “Trust” Layer)
- [ ] Entity Home: Is your “About Us” page the single source of truth for N-A-P?
- [ ] Consistency: Do LinkedIn, Crunchbase, and your site state the exact same facts?
- [ ] Co-Occurrence: Is your brand mentioned alongside keywords on other sites?
Phase 4: Measurement (The Similarweb Suite)
- [ ] Referral Check: Are you tracking traffic from chatgpt.com and perplexity.ai?
- [ ] Share of Voice: Are you monitoring your brand’s visibility in AI answers?
- [ ] Keyword Gap: Have you identified the “Question” clusters you are missing?
🛠️ How to perform the GEO health check in 15 minutes
Don’t wait for a full site audit. You can spot-check your “GEO Readiness” right now on your highest-value page. If you fail more than two of these, you are likely invisible to AI models.
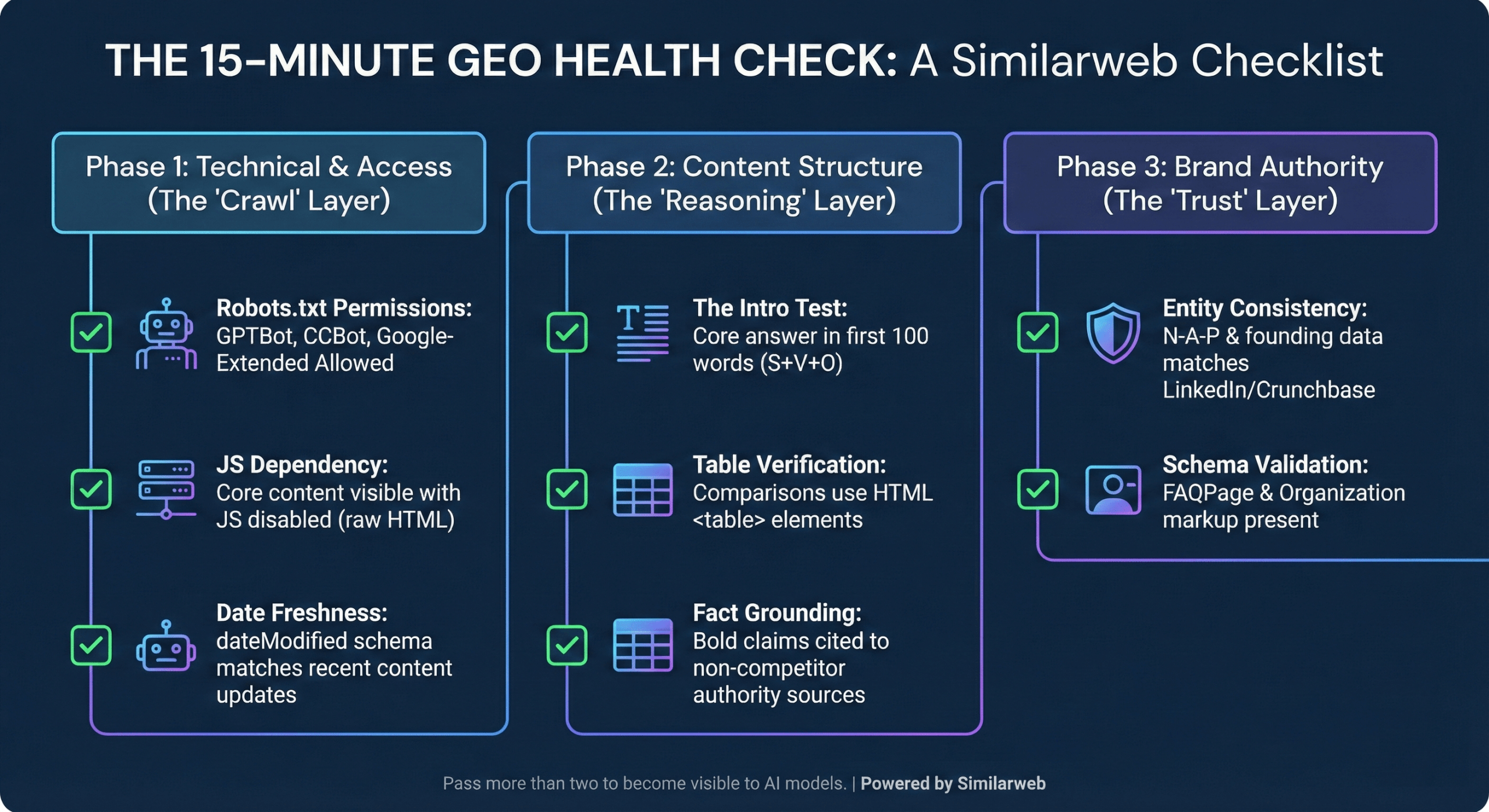
Phase 1: The “Access” Layer (Technical)
- Bot Permissions: Check your robots.txt. Are GPTBot (OpenAI), CCBot (Common Crawl), and Google-Extended allowed? If you block them, you block the conversation.
- JS Dependency: Disable JavaScript in your browser. Can you still see your pricing tables and core product answers? If the screen is blank, the AI is likely seeing a blank screen too.
- Date Stamping: View Page Source and search for dateModified. Does the date match your content, or is it years old? AI craves freshness.
Phase 2: The “Reasoning” Layer (Structure)
- The Intro Test: Read your first 100 words. Do you answer the core user question immediately (Subject + Verb + Object), or is it buried under marketing fluff?
- Table Verification: Are your “Vs” and “Pricing” comparisons actual HTML <table> elements? AI struggles to parse comparisons hidden in paragraphs.
- Fact Grounding: Look at your three boldest claims. Is there a link to a non-competitor, high-authority source (like a government study or major news outlet) next to them?
Phase 3: The “Trust” Layer (Authority)
- Entity Consistency: Open your “About Us” page next to your LinkedIn and Crunchbase profiles. Do the founding dates and HQ locations match exactly? Inconsistencies cause hallucinations.
- Schema Validation: Run the URL through a schema validator. Are you using FAQPage and Organization markup to explicitly label your data?
The bottom line: adapt or fade out
The biggest mistake is thinking GEO is a “hack.” It’s not. It’s about aligning your content with the way machines now learn. The brands that win will be the ones that feed these engines structured, high-density, authoritative facts, not the ones trying to game a keyword counter.
FAQs
What is the difference between SEO, AEO, and GEO?
- SEO (Search Engine Optimization) focuses on ranking links in search results by optimizing for keywords and user clicks.
- AEO (Answer Engine Optimization) focuses on providing direct, concise answers for voice assistants and featured snippets.
- GEO (Generative Engine Optimization) is the evolution of both; it optimizes content for citation by generative AI models by focusing on information density, entity relationships, and structured data.
Does keyword density still matter for AI search?
No, LLMs do not rely on keyword density. Instead, they use Semantic Proximity and Vector Embeddings to understand the relationship between “entities” (concepts, brands, and facts). Repeating a keyword 5 times provides no “information gain,” so AI models filter it out as noise.
Should I block GPTBot and other AI crawlers?
No, blocking bots like GPTBot, CCBot, or Google-Extended is effectively opting out of the future of search. If you block these crawlers, your brand cannot be cited in answers generated by engines like ChatGPT or Perplexity, rendering you invisible to users asking conversational questions.
How do I measure success in Generative Engine Optimization?
Success in GEO is measured by Brand Visibility (AI Share of Voice) and Citations, rather than just clicks. Because AI search is often “Zero-Click,” metrics must shift to tracking how often your brand is cited as the source of truth. You can track specific referral traffic from AI engines using Similarweb.
Why is my organic traffic flat even though I’m optimizing for AI?
AI search often results in Zero-Click interactions because the engine answers the user’s question directly without requiring a site visit. While traffic volume may be lower, the users who do click from AI citations typically have significantly higher intent. The goal is to prevent competitors from becoming the cited source for your keywords.
What is “Grounding” in AI optimization?
Grounding is the mechanism engineers use to prevent AI hallucinations by verifying facts against trusted, authoritative sources. To optimize for this, your content must cite external, non-competing authorities (such as government studies or major news outlets) to validate your claims, signaling to the AI that your data aligns with the “consensus reality”.
How often should I update my content for GEO?
Content should be updated whenever the facts change, and you must use explicit date-stamping. LLMs look for the most current information to avoid “Date Drift.” If your page lacks a clear dateModified schema or precise dates (e.g., “January 2026” instead of “this year”), AI models may discard your data in favor of a clearly dated, older source.

Related Posts




Why AI Engines Cite UGC Over Brand Content And How To Leverage It For AEO

AI Mentions vs. AI Citations: What’s the Difference and Why It Matters for GEO


Wondering what Similarweb can do for your business?
Give it a try or talk to our insights team — don’t worry, it’s free!