




LLMs Comparison: How Different LLMs Contribute to Category Visibility

Over the last year, I kept hearing the same question in marketing and growth conversations: “How do LLMs actually affect traffic?” So I decided to dig in, and to treat LLMs like a real channel, not a hype topic.
Large Language Models (LLMs) are AI systems trained on huge amounts of text so they can understand and generate human language. Models like ChatGPT, Perplexity, and Google’s AI-powered experiences don’t just answer questions anymore. They help people plan trips, compare brands, and decide where to book, buy, or click next.
At their core, LLMs work by predicting the most likely next words based on context. But what really matters for businesses is where those answers appear and how often your brand becomes part of them.
In this article, I compare LLMs not just based on current visibility, but on their potential contribution to a category shaped by how often, and in which contexts, they influence discovery.
But first, let’s start with a few basics.
The Different Types of LLMs and What They’re Good At
The LLM models behave differently, and they influence traffic in different ways. To understand it better, I mapped out the main types of LLMs.

Conversational LLMs (where people think out loud)
Some models, like ChatGPT, are built for conversation. People use them to brainstorm, plan, and ask broad questions. These models tend to surface brands inside explanations and recommendations.
Search-style LLMs (where people want a fast answer)
Other models, like Perplexity and AI-powered search modes, blend real-time search with LLM reasoning. They’re often used earlier in discovery, when the user is still exploring options.
Vertical LLM experiences (where intent is narrow)
There are also LLM-like experiences embedded into specific products, travel, maps, booking, and commerce. These are usually high-intent moments, and brand exposure can be closer to conversion.
Why Comparing LLMs by Category Actually Matters
This is where things got practical for me. I realized that trying to “optimize for all LLMs” is a trap. Attention is limited, budgets are limited, and not every model influences your category equally.
Some models consistently surface the same few brands. Others barely show meaningful visibility at all. That’s why comparison matters. When I compared LLMs properly, I could separate “interesting” from “important.”
This is also where competitive thinking matters. It’s not enough to be visible, you need to be visible compared to your competitors, inside the same prompts and topics.
Some LLMs have limited opportunity to influence a category, simply because of how and when users engage with them. Others represent a much larger potential discovery surface. Comparing LLMs helps separate models with real category-level impact from those with smaller, more constrained potential.
How I Compared LLMs’ Impact Using Similarweb
To move beyond assumptions, I used the LLMs Comparison view in Similarweb’s AI Brand Visibility tool to compare both current visibility and the potential contribution of each LLM to the travel category. I started with the broad view to understand overall patterns, but I didn’t stop there. The real insight came when I narrowed the scope and looked at how LLM behavior changes by topic.
At the all-topics level, the picture was fairly stable. The same leading brands appeared consistently, and the hierarchy didn’t move much. That told me something important early on: when the question is broad, LLMs lean heavily on general brand familiarity. They fall back on names they already associate with travel in a wide sense.
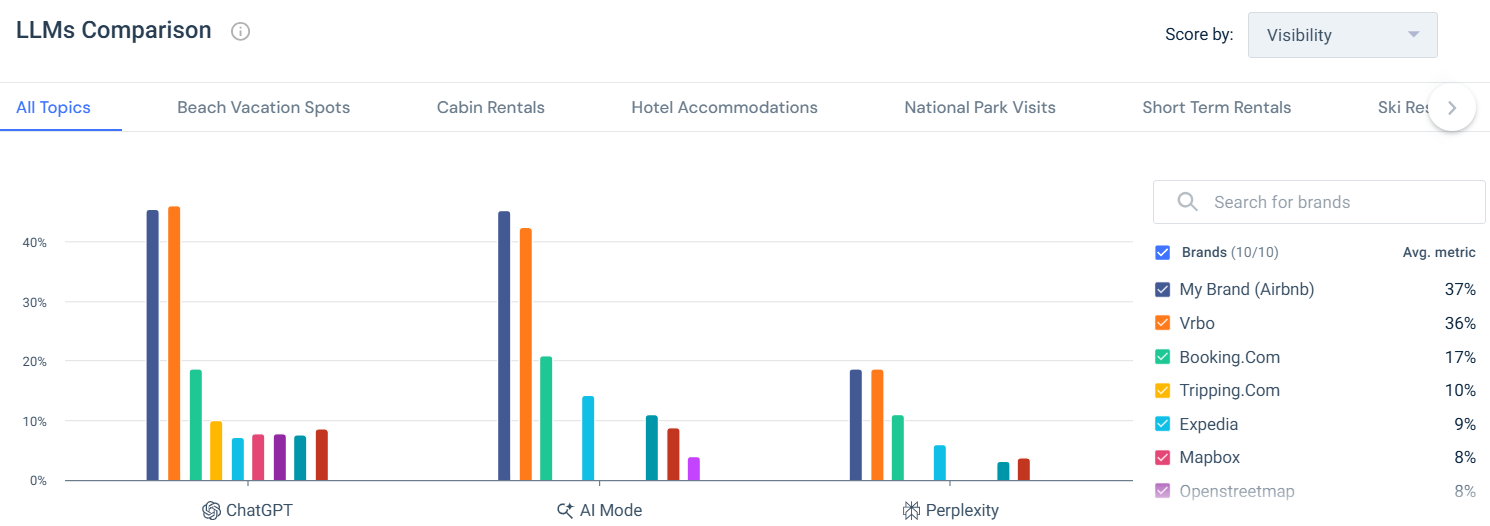
But the moment I switched to a more specific category, Vacation Rental Platforms, the behavior changed noticeably and I found a few interesting insights:
- What stood out right away was that visibility became much more concentrated. Instead of spreading mentions across a wider group of brands, LLMs narrowed their focus. The models seemed more confident, more decisive, and less willing to introduce long-tail alternatives. This told me that when the intent is clear, LLMs don’t try to be exploratory. They try to be helpful and definitive.
- I also noticed that the relative positioning between leading brands stayed tight, but the distance from everyone else grew. That was a big signal. It suggests that in high-intent topics, LLMs don’t just recommend brands, they validate category leaders. If a brand already “belongs” to that specific use case in the model’s understanding, it stays in the answer. If it doesn’t, it drops out almost entirely.
- Another interesting shift was how consistent this behavior was across different LLMs. While the overall visibility levels varied by model, the pattern stayed the same. Once the topic was narrowed, all the LLMs became more selective. That tells me this isn’t a quirk of one model. It’s a general rule of how LLMs handle specific intent.
- What this helped me understand is that LLMs don’t reward general relevance and specific relevance equally. Being broadly associated with travel helps you show up when the question is vague. But when the prompt is focused, only brands with a strong, well-established connection to that exact category remain visible.
- This is also where the strategic value of topic-level analysis really clicked for me. Looking only at the aggregated view can give a false sense of security. A brand might look strong overall, but if it disappears when the topic becomes specific, that’s a real risk. On the flip side, a brand that looks secondary at the category level can still be very competitive if it owns a clear, well-defined niche.
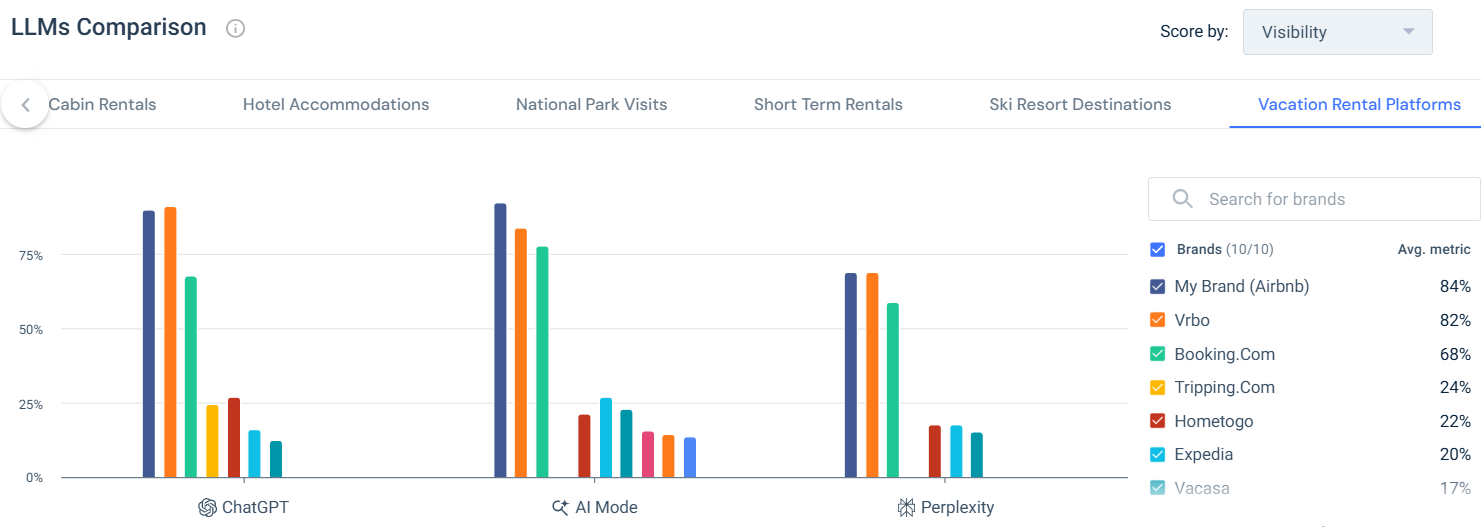
By comparing both views side by side, I could see not just who wins, but where they win. That changed how I think about LLM optimization entirely. Instead of asking how to increase visibility everywhere, the better question became: in which topics does the model already trust us, and where does that trust break down?
That’s the point where the data stopped being descriptive and started guiding real decisions. It showed me that winning in LLMs isn’t about being present in every conversation. It’s about being relevant in the conversations that matter most.
What I Took Away From This
After going through this analysis, my takeaway was simple: it isn’t about chasing every new LLM model. It’s about knowing which models influence your category, and then showing up where those models already expect to find you.
Similarweb AI Search tools made this measurable. Instead of guessing, I could see where visibility was strong, where it was weak, and where the biggest opportunity gaps were. That’s the difference between treating LLMs as a trend and treating them as a real growth channel.
Of course, visibility alone doesn’t tell the full story. When comparing LLMs, it’s also important to consider how much traffic each model receives. An LLM with high visibility but low usage may contribute less overall value than a model with lower visibility and much higher reach. Looking at LLMs this way helps turn visibility into a real opportunity.
FAQs
1. What does it mean when a brand “shows up” in an LLM?
It means the model mentions or recommends the brand when users ask relevant questions. That exposure can influence decisions even if no one clicks a link.
2. Do LLMs actually drive traffic, or just awareness?
They do both. Sometimes they send direct traffic, but even when they don’t, they shape which brands users consider before they ever search or visit a site.
3. What LLMs does Similarweb measure?
Similarweb measures brand visibility across leading LLM experiences, including conversational models like ChatGPT, search-style AI modes, and answer-focused platforms such as Perplexity. This allows teams to compare how different LLMs surface brands in real user scenarios.
4. What metrics does Similarweb use to compare LLMs?
The LLMs Comparison view scores brands based on visibility, showing how frequently each brand appears in LLM responses. This makes it easy to compare relative brand exposure across models using a consistent, comparable metric.
5. Can I compare LLM visibility by topic in Similarweb?
Yes. Similarweb allows you to compare LLM visibility across different topics, such as beach vacations, short-term rentals, or hotel accommodations. This helps reveal how brand visibility changes as user intent becomes more specific.
6. Are all LLMs equally important for marketers?
No. Some models surface brands much more consistently than others. That’s why comparing them matters instead of treating them as one channel.
7. Why does ChatGPT matter so much in this analysis?
Because it’s widely used for planning and research, especially for travel-related questions. That makes it a major discovery surface, not just a chatbot.
8. If my brand is strong overall, will it perform well in every topic?
Not necessarily. As the topic becomes more specific, LLMs focus more on relevance than general brand strength.
9. Can smaller brands compete in LLMs at all?
Yes, but not by trying to win everywhere. Smaller brands tend to perform better when they clearly own a specific topic or use case.
10. Do different LLMs reward different signals?
Yes. Some lean more on overall authority, while others are more sensitive to topical relevance and context.
11. Is LLM optimization the same as SEO?
Not exactly. There’s overlap, but LLMs care more about clarity, consistency, and how a brand is commonly described across the web.
12. What’s the biggest mistake teams make with LLMs today?
Trying to optimize for all models at once instead of focusing on the ones that actually influence discovery in their category.

Related Posts


Why AI Engines Cite UGC Over Brand Content And How To Leverage It For AEO

AI Mentions vs. AI Citations: What’s the Difference and Why It Matters for GEO


How to Do A Competitive Analysis: Complete Guide & Free Templates


Wondering what Similarweb can do for your business?
Give it a try or talk to our insights team — don’t worry, it’s free!