




What Is Llms.txt? Reality vs. Hype

In the early days of the web, search engines had a fundamental need: a standard way to determine where to crawl. That’s why robots.txt became so important.
One small text file at the root of a site provided crawlers with a predictable, machine-readable set of rules, and over time, it evolved into an unofficial but widely respected standard.
We’re in a similar transition point now, with one main difference: The consumer of your content is often a large language model (LLM), not just a classic search engine bot.
Instead of just indexing pages and ranking blue links, Gen AI engines synthesize answers from multiple sources.
At the same time, they have very different constraints: limited context windows, difficulty dealing with complex HTML, and (in many implementations) no persistent, full-site index in the traditional sense.
That’s the context behind llms.txt: a proposal for a root-level, Markdown-based file that doesn’t tell bots where not to go (like robots.txt), but instead tells AI systems which pages you consider most important and how to interpret them.
Over the last year, discussion around llms.txt has split into camps, each with a different POV about the importance of this new file. However, it often seems like everyone is ignoring the real question SEOs should be asking about llms.txt:
“Given limited time and resources, does llms.txt deserve a place in our SEO and AI visibility strategy? And if so, where and how?”
This article is my data-informed answer and opinion on:
- What llms.txt actually is (and what it isn’t).
- How it fits with robots.txt and sitemap.xml.
- What real-world logs and public statements tell us so far.
- Where it genuinely adds value (and where it doesn’t).
- How I’d decide whether to implement it.
Let’s dive in.
1. What is llms.txt? The short, non-hype definition
llms.txt is a small Markdown file served at https://yourdomain.com/llms.txt that lists a curated set of your most important pages, each with a short description, in a tightly defined format.

The llms.txt file is designed primarily for inference time (i.e., when an LLM or agent is actively answering a user’s question), not for training or broad web indexing.
If you like analogies:
- robots.txt: “Here is where you can’t crawl.”
- sitemap.xml: “Here is everything you could crawl.”
- llms.txt: “If you’re trying to answer questions about us, start with these pages.”
That last line is the key.
As SEOs, we’re used to influencing discovery and indexing. Llms.txt tries to influence prioritization under a hard constraint: an LLM can’t load and understand your entire site on every query. You can think of it as a type of “crawl budget”.
1.1. How llms.txt is structured, and why that matters
The official spec (proposed by Jeremy Howard/Answer.AI) defines a strict, simple structure:
- H1 title (#)
- The name of your site (the only required element).
- For an LLM, this is the top-level entity label: “Everything below is about this.”
- Blockquote summary (>)
- A one/two-sentence summary of what you do and who you serve.
- Gives models immediate context even if they only skim the file.
- Optional explanatory paragraphs
- Used to clarify scope or versioning (e.g., “This file covers v2 of our public API docs only”).
- Helpful when your docs, products, or sites have multiple generations or audiences.
- H2 sections (##) that group links by theme
- For example: ## Documentation, ## Guides, ## Product, ## Support.
- Mirrors how LLMs tend to reason in topical “buckets,” not in random URL lists.
- Bulleted lists under each H2 with Markdown links
- Each bullet looks like:
– [API reference](https://example.com/docs/api): Endpoints, parameters, and examples - That combination of anchor text, URL, and short factual description gives the model strong hints about what each page is for and when to use it.
- Each bullet looks like:
- Optional ## Optional section
- A reserved section name. Links here are explicitly lower priority.
- Tools are free to drop these first if the context is tight.
Example of a simple llm.txt file:
From an SEO and AEO point of view, this structure matters because it forces you to:
- Identify your real “source of truth” pages, instead of assuming AI will magically find them.
- Describe pages in concise, factual language, which is exactly the kind of text LLMs are good at classifying and routing with.
You’re not “optimizing the llms.txt file” for rankings, you’re making your content model legible to machines.
1.2. llms-full.txt and .md page variants
Around this spec, a small ecosystem has emerged:
- llms-full.txt
- A single Markdown file containing the full text of your documentation corpus.
- Used as a convenient ingestion endpoint for AI tools and coding agents.
- Docs platforms (like Mintlify) auto-generate this so agents can pull an entire docs set from one URL.
- .md versions of docs pages
- Each docs URL also has a Markdown variant, typically by appending .md:
- https://example.com/docs/api → HTML for humans
- https://example.com/docs/api.md → Markdown for AI
- The llms.txt spec encourages this pattern. nbdev-based projects under Answer.AI already generate Markdown docs by default.
- Each docs URL also has a Markdown variant, typically by appending .md:
Why this matters:
- Markdown strips layout noise (nav, ads, tracking junk) that wastes tokens.
- That reduces cost and truncation risk, which is essential when agents operate inside finite context windows.
If you’re a dev platform or docs-heavy product, this ecosystem already improves agent reliability and developer experience, regardless of whether Google or OpenAI ever officially “use” llms.txt.
2. llms.txt vs robots.txt vs sitemap.xml
Because llms.txt lives at the domain root and ends in .txt, it’s easy for stakeholders to assume it works like robots.txt. It doesn’t.
2.1. Three files, three different jobs
In plain language:
- robots.txt: access control
- “Where can crawlers go?”
- Manages what is and isn’t crawlable (including some AI-training opt-outs).
- sitemap.xml: discovery and coverage
- “What exists on this site?”
- Lists indexable URLs plus metadata like last-modified dates.
- llms.txt: curation and interpretation
- “If you only have room for a subset of pages, which ones matter most, and what are they for?”
- Doesn’t block anything, and it doesn’t list everything. It highlights a small set of high-signal pages and labels them clearly.
The spec explicitly states that llms.txt coexists with (not replaces) robots.txt and sitemap.xml.
2.2. Why the distinction matters
Mis-framing llms.txt leads to bad expectations:
- It does not control crawling or training behavior.
- It does not override robots.txt or meta directives.
- It does not serve as an “AI XML sitemap”.
From a strategy perspective:
- robots.txt is your guardrail.
- sitemap.xml is your catalog.
- llms.txt is your curated reading list with notes, written for AI.
If you treat llms.txt like a second sitemap and dump 200 URLs into it, you’ve missed the point, and you’re actively making life harder for any agent that tries to use it.
3. What problem is llms.txt actually trying to solve?
To decide if llms.txt is worth your attention, you need to be clear on the friction it addresses.
3.1. How LLM-based systems “see” your site
Classic search engine crawlers:
- Continuously crawl and update large slices of the web.
- Render JavaScript where needed.
- Maintain long-lived indexes used for ranking.
Many LLM-based systems, especially in “browsing” modes or agent setups:
- Fetch content at query time, not as part of an ongoing crawl.
- Often, generative engines don’t execute complex JavaScript, meaning JS-only content is invisible to them.
- Operate within strict token windows: they may only “see” a fraction of the HTML they fetch.
The result:
- Navigation, cookie banners, and clutter often appear before your core content.
- Long, dense pages can get truncated, cutting off key sections.
- Important docs hidden behind JS-heavy nav structures are poorly understood or missed.
Similarweb’s research on GenAI and publishers shows how these dynamics play out: AI Overviews increasingly satisfy user intent on the SERP, driving “zero-click” behavior and reducing visits to the underlying sites.
That same “answer-first” pattern applies when LLMs browse your site directly: they’re trying to get in, grab exactly what they need, and get out. Quickly.
3.2. Typical failure modes from an AI visibility standpoint
Because of those constraints, we see failure patterns like:
- AI answers that rely on old blog posts rather than updated ones.
- Third-party explainers outranking your own product guides as the cited source.
- Misstated pricing, limits, or policies because the canonical page is long, salesy, or buried.
- Incomplete or hallucinated API behavior because reference docs are fragmented or noisy.
Traditional SEO is mostly about being discoverable and indexable. In the AI era, we also need to be legible and prioritized within narrow context windows.
3.3. llms.txt as a targeted mitigation
Llms.txt doesn’t pretend to fix everything. But it does attack one narrow yet important question:
If a model can only look at a handful of your pages, how do you help it pick the right ones and understand what each is for?
It does that by:
- Offering a curated list of high-value URLs.
- Presenting them in Markdown to minimize layout noise.
- Including short, explicit descriptions (e.g., “API v2 reference,” “current self-serve pricing,” “getting started guide”).
From a GEO/AEO perspective, llms.txt is less about chasing a ranking factor and more about increasing the odds that, if AI tools use your site, they start with the right content.
4. How the SEO industry actually sees llms.txt
If you read across SEO blogs, dev docs, and product updates, four distinct positions show up.
4.1. The skeptics: “Not worth it (yet)”.
This point of view is driven by the current adoption reality:
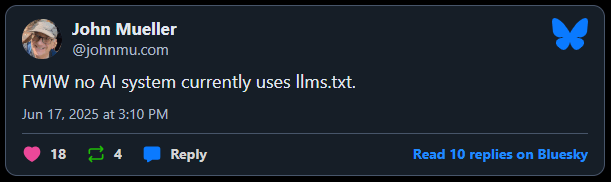
- Googlers have publicly stated that no Gen AI system currently uses llms.txt, and compared it to the old keywords meta tag: something SEOs might obsess over, but that search engines ignore.

- Early log-file analyses show very few consumer-facing LLM crawlers (GPTBot, Google-Extended, PerplexityBot, ClaudeBot) requesting /llms.txt at any scale.
From that vantage point:
- There’s no evidence that llms.txt improves rankings, AI Overviews presence, or traffic.
- No major LLM vendor has said “we treat this as a signal.”
My SEO take:
If you’re still dealing with crawl issues, thin content, weak website infrastructure, or fragile technical SEO, this camp is right: llms.txt does not belong anywhere near the top of your backlog.
4.2. The pragmatic futurists: “Cheap insurance”.
This group agrees the impact is unproven, but looks at the cost differently:
- A simple, 5-15 URL llms.txt file takes under an hour to draft.
- Updating it a couple of times a year is negligible compared with most content or dev projects.
- It’s essentially an option: low downside, potential upside if/when adoption grows.
They also value the internal exercise:
- To write a good llms.txt, you must agree on your canonical, source-of-truth pages.
- That often surfaces outdated docs, overlapping content, or internal misalignment (which are issues you should fix anyway).
My SEO take:
If your fundamentals are in good shape and you already care about AI visibility and Generative Engine Optimization, I’m aligned with this camp.
Think of llms.txt as “future insurance + content clarity,” not as a lever you report on quarterly.
4.3. Docs & agent champions: “It’s useful right now”.
In developer ecosystems, the discussion is much less theoretical.
- Docs platforms generate llms.txt, llms-full, and .md exports out of the box to help coding agents and AI tools ingest docs.
- Anthropic and others highlight LLM-friendly Markdown docs as a best practice for tools and agents to consume.
- Benchmarks from teams working on code assistants show that AI agents guided by llms.txt-structured docs often outperform those that rely solely on semantic search across unstructured HTML. This is another proof that AI agents are only as good as the data integrated with them.
Here, the upside is tangible:
- Better agent reasoning over your docs.
- Lower token usage and cost when AI agents fetch Markdown instead of full HTML.
- Fewer AI-related support tickets because “the AI” is finally reading the right docs.
My SEO take:
If your product is developer-first or heavily API-based, I’d treat llms.txt and its ecosystem as a DX/docs requirement, not an SEO experiment.
The value shows up in developer adoption and retention, even if it never shows up in “organic sessions” reports.
4.4. AI SEO/GEO enthusiasts: “Be the answer”.
This camp is focused on the bigger shift from clicks to answers.
- Similarweb’s GenAI research shows AI chatbot traffic growing fast: in June 2025, major AI platforms generated over 1.1 billion referral visits, up 357% year-over-year.
- At the same time, Similarweb’s reports on publishers show substantial traffic drops for many news sites as Google’s AI Overviews satisfy more queries without clicks.
In that world, GEO (Generative Engine Optimization) is about:
- Being selected and cited inside AI answers, not just ranking in classic SERPs.
- Making sure generative AI engines describe your brand accurately when they answer in your space.
For this group, llms.txt is one more supporting signal:
- It doesn’t replace schema, internal links, or entity work.
- It does give you a clean way to say, “These are our authoritative answers.”
My SEO take:
Strategically, I agree with the GEO direction. Tactically, llms.txt is a small, aligned tactic, not the core of your AI optimization strategy.
Strong, straightforward, authoritative content still does most of the heavy lifting.
5. What the data says (so far)
Strip out the hype, and you get a reasonably consistent picture.
5.1. Adoption is growing, but still niche
- The llms.txt spec has stable documentation and a growing tool ecosystem (CLI tools, plugins for popular doc generators, CMS integrations).
- Adoption is heavily concentrated in developer tools, SaaS docs, AI-aware agencies, and early GEO experiments.
Relative to the entire web, it’s still an early adopter pattern, not a mainstream standard.
5.2. For classic SEO and AI Overviews, llms.txt is neutral today
Across public statements and independent experiments:
- There is no evidence that llms.txt:
- Improves organic rankings
- Increases AI Overview inclusion
- Moves traditional SEO KPIs in a repeatable way
Today, classic ranking systems still respond to technical health, relevance, authority, and user signals. Not to llms.txt.
5.3. For agents, tools, and AI-native docs, it already has jobs
On the other hand:
- Tool builders and docs platforms are already using llms.txt and llms-full.txt as ingestion endpoints for LLM-based tools and MCP servers.
- That doesn’t register as “more organic traffic,” but it does show up as:
- Better agent-driven onboarding
- More accurate AI-generated examples
- Less friction when developers use AI assistants
If your product’s success depends on developers understanding your docs via AI tools, this matters.
6. Should you implement llms.txt? A practical framework
With so many pros and cons to llms.txt, SEOs need to weigh the benefits it can bring to their site vs. the potential time waste of a 0-impact project. We don’t always have all the resources we need to carry out SEO tasks, so why add tasks that don’t result in more traffic or revenue for us?
Let’s get concrete, here’s how I’d prioritize it:

6.1. High priority: dev platforms and docs-heavy products
You should strongly consider llms.txt (plus llms-full and .md docs) if:
- You’re API-first or developer-first.
- You maintain a substantial public docs site.
- Your users already rely on:
- IDE assistants
- Embedded AI in docs
- Agents that fetch docs via HTTP
In that context:
- llms.txt is part of building AI-native documentation, not a speculative traffic play.
- It’s aligned with how LLM-aware dev tooling is evolving.
My SEO take:
Own this as a product/docs initiative, with the SEO team as a stakeholder.
Measure success via developer outcomes (time-to-first-success, reduced support burden), not ranking charts.
6.2. Medium priority: mature, content-rich sites exploring GEO
You should consider a lightweight llms.txt if:
- Your technical SEO and content fundamentals are solid.
- You have clear “pillar” content and stable product docs.
- You’re actively tracking AI behavior:
- Using Similarweb’s AI traffic tracker ( in the AI Search Intelligence suite) to see which chatbots send traffic to which URLs.
Here, a small llms.txt is:
- A low-cost experiment.
- A forcing function to clarify your 5-15 actual source-of-truth pages.
- A nice complement to your GEO/AEO initiatives.
My SEO take:
Invest ~45-60 minutes to create a curated llms.txt, then review it a few times a year alongside your normal content audits. Don’t sell it internally as a “growth lever”, present it as readiness + modeling clarity.
6.3. Low priority: sites still fighting the basics
You should not prioritize llms.txt yet if:
- You have unresolved crawlability, indexability, or speed issues.
- Your content is thin, outdated, or poorly structured.
- Your website structure and internal links make it hard for humans and search bots to navigate.
In that world:
- Fixing fundamentals will significantly move your metrics.
- llms.txt almost certainly won’t, at least not in a measurable way.
My SEO take:
Keep llms.txt in your 20% “experimental” bucket for later. Get the 80% core SEO work stable first.
7. How to create a proper llms.txt (without overdoing it)
If you’ve decided to test llms.txt, here’s a pragmatic way to do it.
7.1. Step 1: Decide scope and owner
First, define what the file describes:
- Entire site
- Just docs
- Just one product or subdomain
For most SaaS and dev companies, starting with docs only is realistic and high impact.
Then assign ownership:
- Content SEO: curate URLs and descriptions.
- Engineering/DevOps: deploy the file to /llms.txt and add the X-Robots-Tag: noindex header.
If no one owns it, it will drift out of date (which is worse than not having it).
7.2. Step 2: Inventory your “AI-worthy” pages
This is where the real thinking happens. Ask yourself: If an AI could only look at 5-15 URLs, which ones would we trust to represent us?
Pages to include in llms.txt
- Pillar guides and onboarding hubs
- API references and core SDK docs
- Evergreen “What is X?” or “How to do Y with [Brand]” explainers
- High-value FAQs and troubleshooting hubs
- Stable pricing and policy pages
Pages to exclude from llms.txt
- Thin campaign LPs or short-lived promos
- Extremely salesy pages with little factual content
- Purely navigational or legal boilerplate
This exercise itself is valuable: it often exposes gaps and inconsistencies in your content strategy.
7.3. Step 3: Draft the file in Markdown (keep it factual and concise)
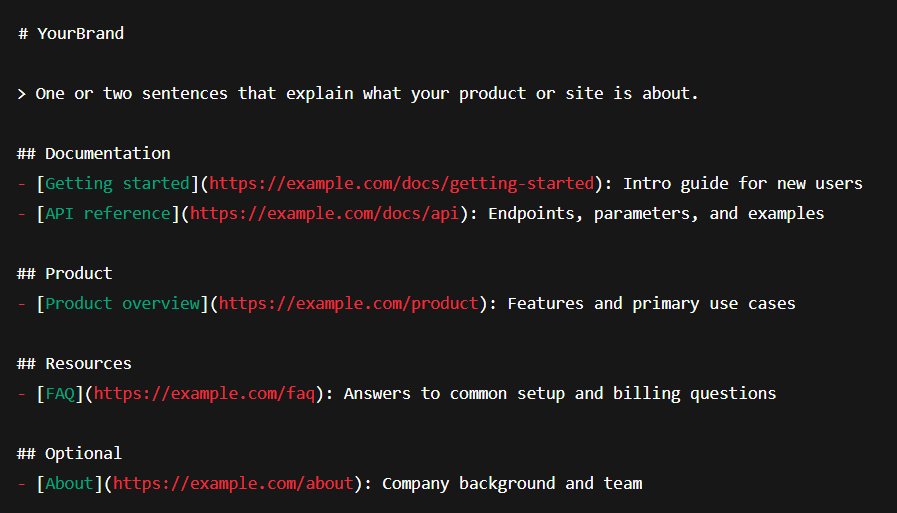
Using the spec, you might end up with something like:
# YourBrand
> YourBrand is a [short, factual description: what you do, for whom, and in what use cases].
This file provides a curated guide to our most important public resources for large language models and AI assistants.
## Documentation
- [Getting started](https://example.com/docs/getting-started): Introductory guide for new users
- [API reference](https://example.com/docs/api): Endpoints, parameters, and usage examples
- [Authentication](https://example.com/docs/auth): How to authenticate and manage API keys
## Product
- [Product overview](https://example.com/product): Features, plans, and core use cases
- [Pricing](https://example.com/pricing): Current pricing tiers and billing details
## Support & FAQ
- [FAQ](https://example.com/faq): Answers to common setup and account questions
- [Status](https://status.example.com): Live service status and incident history
## Optional
- [About](https://example.com/about): Company background and team
Why this works:
- Link text like “API reference” or “Pricing” makes intent obvious.
- Short descriptions tell an LLM which URLs are relevant for which topic.
- H2 sections mirror how models chunk and reason about related content.
Think of it as internal linking + schema for AI, written in Markdown.
7.4. Step 4: Deploy at /llms.txt and control indexing
Implementation basics:
- Serve the file at https://yourdomain.com/llms.txt.
- If your CMS can’t place it at the root folder, use a clean 301 redirect from /llms.txt to its actual location.
- Open it in a browser to verify it renders as plain text.
If you don’t want the file itself to appear in search results, configure your server to send an X-Robots-Tag: noindex header for that path.
You want AI engines and tools to easily find the file. You don’t need it cluttering up SERPs.
7.5. Step 5: Set a light maintenance rhythm
llms.txt should evolve with your site:
- Review when you launch a major new product or docs area.
- Update when you deprecate or rewrite canonical pages.
- Do a quick quarterly check:
- Are all URLs live?
- Do descriptions still match reality?
- Are we missing obvious “sources of truth”?
If you can’t commit to basic maintenance, it’s better to wait than to ship stale guidance.
8. Monitoring and learning from llms.txt
You won’t (yet) see a neat “llms.txt → traffic spike” pattern in your dashboards, but you can use data to learn whether it’s being touched and whether AI visibility is changing.
8.1. What to monitor
1. Server and log-file data
- Check logs for hits to /llms.txt and /llms-full.txt by AI or agent user agents.
- Over time, this tells you whether any engines, tools, or agents start relying on the file.
If you want to do this at scale, you don’t have to write your own log parser. Similarweb’s Site Audit tool integrates log-file summary data from log analyzers like Logz.io and other tools, so you can overlay bot behavior with crawl and technical insights instead of treating logs as a separate, one-off project.
2. AI chatbot traffic
- Use Similarweb’s AI Traffic tool to see:
- Which AI chatbots (ChatGPT, Gemini, Perplexity, etc.) send traffic to your site
- Which pages receive AI-originated visits
- That helps you understand whether the URLs you surfaced in llms.txt are actually part of AI-driven sessions.
3. Developer and support feedback (for dev products)
- Track whether AI-assisted onboarding feels more accurate or requires fewer escalations after you rework docs for LLM legibility and expose them via llms.txt.
8.2. What not to expect (for now)
Be realistic:
- Don’t expect immediate ranking lifts, AI Overview inclusion boosts, or a clean “before/after llms.txt” traffic graph.
- Any impacts will likely be indirect, via better AI understanding and behavior, not because llms.txt has become a first-class ranking signal.
That’s why I recommend positioning llms.txt internally as a forward-looking optimization and clarity tool, not a primary SEO KPI lever.
9. Common llms.txt mistakes to avoid
If you do implement llms.txt, avoid these traps:
- Treating it as a ranking factor
There’s no evidence that it impacts rankings or AI Overviews today. Don’t oversell it. - Turning it into a mini-sitemap
Dumping dozens or hundreds of URLs defeats the point. The value lies in selective curation. - Letting it go stale
If your canonical URLs change and llms.txt still points at old pages, you’re undermining your own intent. - Using it instead of robots.txt for control
Llms.txt doesn’t block crawling or training. Use robots.txt and meta directives for that. - Ignoring content quality
A beautifully structured llms.txt that points to vague, shallow, or confusing content does nothing. AI systems still prefer strong, well-structured content, just like users.
Treat llms.txt like early schema markup or early XML sitemaps: worth testing after the fundamentals are in place, not instead of them.
10. The bigger picture: AI visibility beyond llms.txt
llms.txt is interesting because it sits exactly where:
- User behavior is shifting from clicking links to getting direct answers in AI engines.
- Machines increasingly need clean, structured, high-signal content to make those answers accurate.
Whether llms.txt becomes widely adopted or not, the direction is clear:
- AI engines reward content that is:
- Well-structured and chunked
- Factually strong and current
- Easy to interpret without relying on heavy layout or client-side scripts
- Search behavior is moving toward:
- AI chatbots and GenAI experiences
- “Zero-click” answers where the AI becomes the primary interface
In this “new world”, the SEO job shifts from “get us ranked” to “make sure we are the trusted, quoted source when AI systems answer questions in our space”.
That’s essentially Generative Engine Optimization (GEO): structuring clear, factual, self-contained content so answer engines choose you when they assemble responses.
llms.txt can support that, but only as a thin layer on top of a solid content strategy, strong entities and structured data, clean technical foundations, and a real view of how AI-driven traffic already behaves (which you can track with Similarweb’s GenAI visibility and AI Chatbot Traffic tools).
In practice, llms.txt makes the most sense for dev and docs-heavy products, is a low-cost experiment for mature sites, and should sit behind core SEO work for everyone else.
Don’t build your AI optimization strategy around llms.txt. Build it around clarity, authority, and structure, then use llms.txt as one more small, aligned step in that direction.
FAQs
What is llms.txt in simple terms?
Llms.txt is a Markdown file at your domain root that lists a small set of your most important pages for AI systems, each with a short description. It’s meant to guide LLMs and agents toward your “source of truth” content when they answer questions about your brand.
Does llms.txt improve SEO rankings or AI Overviews today?
No. Right now, llms.txt is not a ranking factor and doesn’t directly influence AI Overviews. It’s best treated as future-facing documentation and agent support, not as a way to boost website traffic.
Do ChatGPT, Gemini, or Claude actually use llms.txt?
Publicly, major consumer assistants have not confirmed using llms.txt as a standard input for answers. However, some documentation platforms and agent frameworks already rely on llms.txt, llms-full.txt, and Markdown docs to power dev tools and coding assistants, so it’s gaining traction in those ecosystems.
How is llms.txt different from robots.txt?
Robots.txt controls where crawlers can go on a website. Llms.txt doesn’t block anything, but simply highlights a curated set of URLs and explains what they’re for, helping AI systems prioritize the right content.
Is llms.txt just a sitemap for AI?
Not exactly. A sitemap lists many or all indexable pages for discovery. llms.txt lists only a handful of high-value, canonical URLs and labels them with concise descriptions.
Who should implement llms.txt first?
Prioritize it if you’re an API-first/developer platform. Nice-to-have if you’re a mature brand with solid SEO basics and you’re already investing in GEO/AEO. Skip for now if you still have core SEO issues.
How does llms.txt relate to Generative Engine Optimization (GEO)?
GEO is about being selected and cited inside AI answers, not just ranking in SERPs. llms.txt supports GEO by giving AI systems a clear list of the pages you consider authoritative. However, it’s a supporting tactic; strong, structured, trustworthy content is still the core of any GEO strategy.
How can I see if AI chatbots are sending traffic to my site?
You can use Similarweb’s GenAI Intelligence and AI Chatbot Traffic capabilities to see which AI chatbots (like ChatGPT, Gemini, Perplexity, and others) refer traffic to your site and which pages they hit. That helps you connect llms.txt and AI legibility work to real-world behavior.
How many URLs should I include in llms.txt?
For most sites, 5-15 URLs is ideal. Focus on pages that clearly explain what you do, how to use your product, your pricing and policies, and your core docs or FAQs. If a page wouldn’t make sense as a standalone “source” in an AI answer, it probably doesn’t belong in llms.txt.
Can llms.txt hurt my SEO if I get it wrong?
Used correctly, llms.txt shouldn’t hurt traditional SEO at all. It doesn’t change how classic search crawlers index your site, and you can mark the file itself noindex. The real risk is strategic: if you point AI tools at outdated or non-canonical pages, you might reinforce the wrong messages. That’s why light, ongoing maintenance is essential once you ship it.

Related Posts




Why AI Engines Cite UGC Over Brand Content And How To Leverage It For AEO

AI Mentions vs. AI Citations: What’s the Difference and Why It Matters for GEO


Wondering what Similarweb can do for your business?
Give it a try or talk to our insights team — don’t worry, it’s free!