




Topical Authority in LLMs: How Strongly a Model Associates Your Brand With a Category

A few months ago, I ran a quick test. I opened ChatGPT, Gemini, and Perplexity side by side, typed “best tools for website traffic analysis,” and compared what came back. The results were different, not just in phrasing, but in which brands each model actually recommended.
That got me thinking hard about something: it’s not just about whether an LLM mentions your brand. It’s about how strongly that model ties your brand to a specific topic or category. That connection, how confidently a model says “Brand X is a leader in Category Y”, is what I’m calling topic authority in LLMs.
And if you’re doing any kind of search visibility work right now, this matters more than most people realize.
What Is Topical Authority in LLMs (and Why It’s Different From Regular Topical Authority)
If you’ve worked in SEO for a while, you know topical authority. The idea is that Google rewards sites that cover a topic deeply and consistently. Write enough quality content about a subject, build the right links, get cited by the right sources, and Google starts seeing you as a go-to resource on that topic.
LLMs work differently. They learned what they know during training, which means the associations they formed between brands and categories are baked into the model. When a user asks ChatGPT “what’s the best CRM software,” the model isn’t doing a fresh search. It’s drawing on patterns from millions of documents it read during training, reviews, comparison articles, forum posts, news coverage, you name it.
So topic authority in LLMs is really about this: how deeply embedded is your brand-category connection in the training data that shaped a model’s understanding of your space?
I found that this framing changes how you think about content strategy. You’re not just optimizing for rankings anymore. You’re trying to shape the associations a model forms, or has already formed, about your brand.
Why Some Brands Win in LLMs and Others Don’t
When I started looking into this more seriously, I did a bunch of prompt testing across different models. What I found is that certain brands come up consistently and confidently, while others get mentioned as afterthoughts, or not at all.
A few things seem to drive this:
Volume of third-party mentions
If a brand gets talked about a lot across review sites, comparison articles, and industry publications, that pattern shows up in training data. It’s not just about your own content. It’s about what other people say about you.
Consistency of category signals
If every article that mentions your brand also consistently mentions the same category or use case, the model learns that association. If your brand shows up in five different contexts with no clear through-line, the model’s association with any single category is weaker.
Depth of topical coverage
Models seem to favor brands that have produced or inspired deep content around a specific topic, not just breadth. A brand with 200 shallow articles across 20 topics is probably going to have weaker topic associations than a brand with 50 really thorough pieces all tightly focused on one area.
Recency and source authority
The quality and authority of sources that mention your brand matter. A mention in a Forbes article, a well-known industry blog, or a major comparison guide carries more weight than a low-traffic blog post.
How Different LLMs Associate Brands With Topics, And Why They Don’t All Agree
This is where things get really interesting. I did a deep dive using Similarweb’s LLMs Comparison feature, which lets you see how different models, ChatGPT, Gemini, Claude, Perplexity, and others, contribute to brand visibility across categories. And the differences are striking.
I’ll walk through the full analysis in the next section, but first, here are the key patterns I found.
ChatGPT tends to favor established, well-documented brands
Because OpenAI’s models were trained on a massive and broad dataset, they tend to reflect mainstream consensus. Brands that have been written about extensively in mainstream publications, large comparison sites, and popular review platforms do well here. If you’re in a category where there’s already a lot of web content with a clear winner narrative, ChatGPT will usually reinforce that narrative.
Perplexity is more responsive to recent and cited sources
Since Perplexity actively retrieves content when answering queries, its brand associations are more dynamic. I found that brands with strong recent press coverage and high-authority backlink profiles tend to perform better on Perplexity than on models that rely purely on static training data. This means a brand can gain visibility on Perplexity faster than on ChatGPT, where the model weights update much less frequently.
Gemini shows a noticeable tilt toward brands with strong Google-indexed presence
This makes sense when you think about it. Google’s data and infrastructure play a role in how Gemini was trained and how it retrieves information. Brands with strong organic presence, rich structured data, and high visibility in Google’s ecosystem tend to come up more in Gemini responses. For those of us doing SEO, this is actually good news: your existing Google-facing work isn’t wasted.
Claude tends to be more cautious and hedged in brand recommendations
From what I’ve seen, Claude is less likely to give a definitive “best brand” answer in competitive categories, and more likely to offer a range of options or caveats. This means brand-category associations in Claude can feel weaker even for well-known players. Getting Claude to associate your brand with a category strongly probably requires being cited in very authoritative, high-quality content, the kind that a model trained with safety and accuracy in mind would treat as reliable.
What does all this mean practically?
Your brand’s topical authority isn’t universal across LLMs. It’s model-specific. A brand that dominates in ChatGPT responses for “project management software” might barely appear in Gemini responses for the same query. Similarweb’s tool compares LMMs and makes this visible in a way that used to require manual prompt testing, and that kind of cross-model visibility is becoming a core part of how I think about GEO strategy for our clients.
How to Build (and Measure) Topical Authority in LLMs
Before I talk about content strategy, I want to start with measurement.
Because the first thing I learned is this: you can’t improve LLM topic authority if you don’t know how different models currently associate your brand.
Start with measurement to find your topical authority opportunities
I pulled data from Similarweb’s LLMs Comparison tool and analyzed how brands show up across models and categories. Instead of manually prompting ChatGPT, Gemini, Claude, and Perplexity one by one and trying to track patterns in a spreadsheet, I wanted structured visibility.
When I looked at the “All Topics” view, the differences between models were immediately clear. Some brands were relatively balanced across ChatGPT, Gemini, AI Mode, and Perplexity. Others were heavily concentrated in one model and much weaker in others. Gemini, for example, showed stronger concentration toward certain dominant brands. Perplexity’s distribution was flatter. ChatGPT tended to reflect more established, widely documented players.
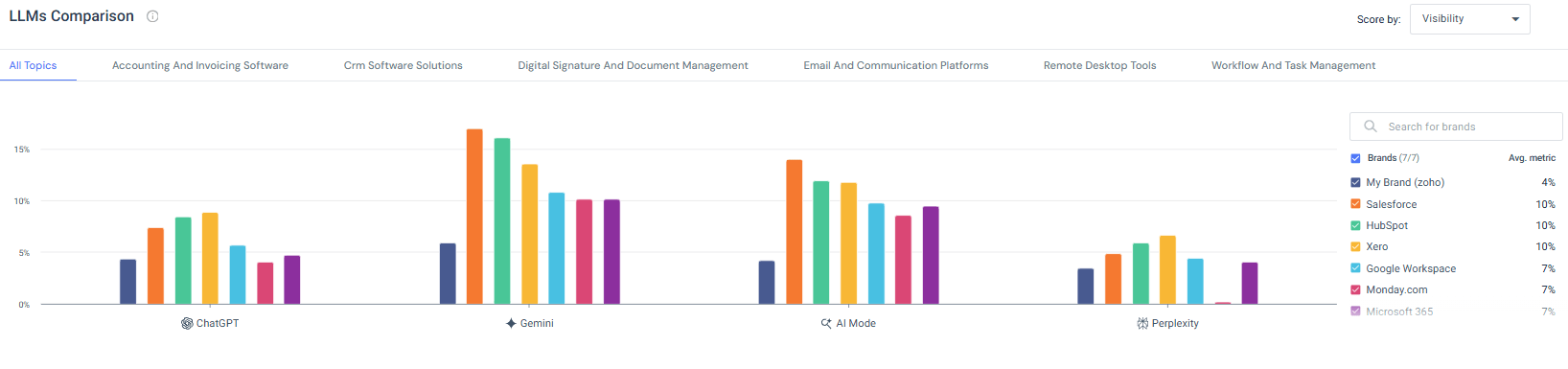
What stood out to me wasn’t just who was leading. It was how uneven the visibility was across models.
Topical authority is not universal.
A brand can look strong overall, but if most of that strength is coming from one model, that’s a vulnerability. If that model changes behavior, retraining patterns shift, or usage trends move elsewhere, your visibility can drop quickly.
Then I zoomed in on a single category: CRM Software Solutions.
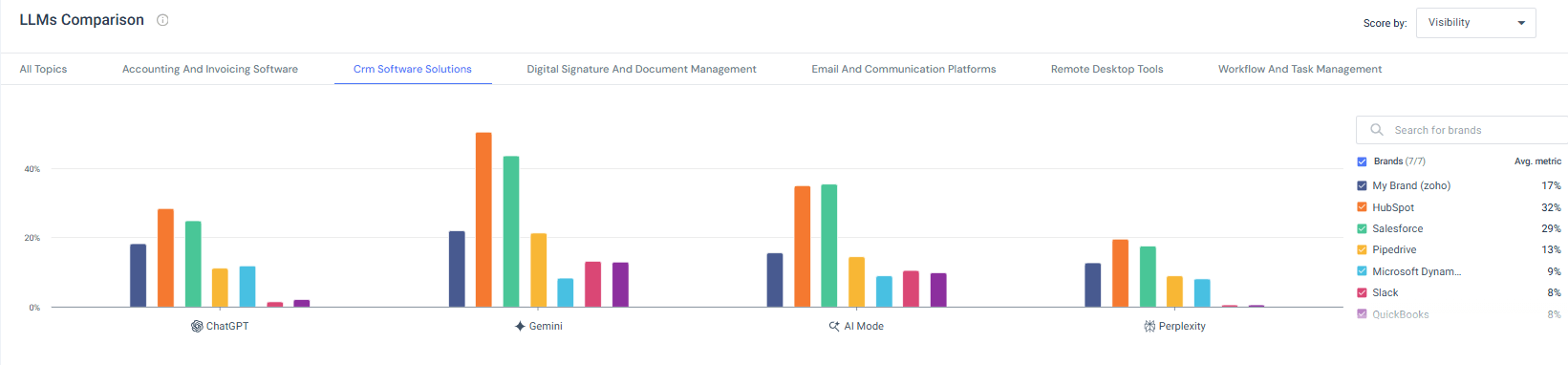
This is where things became even clearer. In the CRM view, HubSpot and Salesforce dominate Gemini very strongly. ChatGPT shows a more distributed spread of visibility. Perplexity compresses overall visibility but still reflects category leaders. Smaller players appear inconsistently across models, sometimes visible in one and almost invisible in another.
That’s when the idea of model-specific topic authority really clicked for me.
If I were working with a CRM brand and saw strong Gemini visibility but weaker ChatGPT presence, I wouldn’t treat that as “we’re doing well.” I’d treat it as a signal. Each model forms brand-category associations differently, based on different training data, different weighting, and in some cases different retrieval behavior.
Once I understood that, I identified where we’re strong and where we’re weak, and decide where to focus.
Standardize how you name the category
Consistency in language turned out to be more important than I expected. If your brand calls itself web analytics in one place, traffic intelligence somewhere else, and a digital data platform somewhere else, the association becomes fuzzy. Models are pattern recognition systems. If the pattern isn’t consistent, the association weakens. I’ve become much more disciplined about category framing across PR, homepage copy, guest posts, and metadata. If we want to own a category, we have to name it consistently.
Focus on the main topics
During the analysis across models, I started seeing patterns in what actually strengthens brand-category associations.
The first thing I do is narrow the focus. I’ve seen over and over that brands trying to own five or six loosely connected topics rarely build strong associations in LLMs. Models learn through repetition. If your brand consistently appears next to one core category across your own content and third-party mentions, that association becomes strong. If it appears scattered across multiple unrelated areas, the signal weakens. Depth builds authority. Breadth dilutes it.
Increase your brand citations around the primary topic
When I analyze brands that consistently show up in model responses, they are heavily cited by industry publications, comparison sites, roundup articles, and respected blogs. That doesn’t happen by accident.
To build that kind of presence, I focus on getting the brand included in high-quality comparison lists, contributing expert insights to industry publications, earning quotes in trend reports, and building relationships with editors who write about the category. I also look at the top-ranking comparison and “best tools” pages in the space and actively work to be included in them.
The more often respected sites connect your brand with a specific category, the more embedded that association becomes in the broader content ecosystem, and the more likely it is that models internalize that connection.
Create content around category-defining questions
I also pay close attention to category-defining questions. When I look at brands that appear confidently in LLM answers, they almost always have strong content around the core questions of their space. What is the best tool for X? How does Y software work? What’s the difference between A and B? These aren’t thin landing pages. They’re structured, clear, and genuinely helpful resources. If your brand contributes meaningfully to answering those foundational questions, there’s a much higher chance it influenced how models understand the category.
Keep content fresh & updated
And then there’s freshness. For retrieval-based models like Perplexity, recent coverage can move the needle relatively quickly. Updated guides, fresh press mentions, and new comparison content can influence visibility faster than static training-based models. Even for models that rely more heavily on training data, future training runs will happen. Content that remains accurate, well-maintained, and authoritative is more likely to be included and weighted in the next iteration.
What This Means for Your GEO Strategy Right Now
I’ll be direct: if you’re an SEO or content marketer and you haven’t started thinking about LLM visibility alongside Google visibility, you’re already a step behind. I’m not saying Google is going away, it’s not, but the percentage of information-seeking behavior happening through LLMs is growing fast, and that trend isn’t reversing.
The brands that are going to be well-positioned in the next few years are the ones that are building real, deep topic authority, the kind that shows up in both Google rankings and LLM responses. The underlying work is mostly the same: produce great content, earn credible third-party coverage, and be consistent about what you stand for. But the measurement and strategy layer needs to evolve.
Start by understanding where you actually stand. Use tools like Similarweb’s LLM comparison to get a clear picture of how different models see your brand in your category. Run your own prompt tests. Ask the models directly: “What are the leading companies in [your category]?” See what comes back.
Then close the gaps. Build the content. Earn the coverage. Own the category.
FAQs
What is topical authority in LLMs?
Topical authority in LLMs refers to how strongly and consistently a language model associates a specific brand or website with a particular topic, category, or use case. The stronger that association in the model’s training data, the more likely the brand is to be mentioned when users ask relevant questions.
Is topical authority in LLMs the same as topical authority for SEO?
They’re related but not identical. Topical authority for SEO focuses on convincing search engines that your site covers a topic deeply and deserves to rank. Topical authority in LLMs is about the associations already baked into a model’s training, it’s less about real-time signals and more about the cumulative weight of coverage your brand received before the model’s training cutoff.
How do LLMs decide which brands to recommend?
LLMs don’t “decide” in a conscious way, they predict which response is most appropriate based on patterns in their training data. Brands that were mentioned frequently, consistently, and in authoritative sources are more likely to come up in relevant responses. There’s no single factor; it’s the overall pattern of coverage.
Why does my brand appear in ChatGPT but not Gemini (or vice versa)?
Different models were trained on different datasets, with different weighting and data sources. ChatGPT, Gemini, Claude, and Perplexity each have their own approach to training and retrieval. Brands can have very different levels of topical authority across models depending on where their coverage lived, how recent it was, and which sources the model prioritized.
Can I improve my brand’s topical authority in LLMs?
Yes, though it takes time. The most effective approaches are: publishing deep, authoritative content focused on your core category, earning mentions in respected third-party publications and comparison sites, being consistent in how you describe your brand and category, and staying active so your content is positioned well for future training updates.
Does my own website’s content affect my topical authority in LLMs?
Yes, but it’s not the only factor, and arguably not the most important one. LLMs learn from a wide range of sources, and third-party coverage (what others say about your brand) carries a lot of weight. Your own content matters, but it works best in combination with strong external coverage.
How does Perplexity differ from ChatGPT in how it handles brand authority?
Perplexity retrieves content at query time rather than relying solely on static training data, which makes it more responsive to recent coverage and high-authority sources. This means brands can build visibility on Perplexity faster through fresh content and press coverage. ChatGPT’s brand associations are more heavily tied to its training data, which is updated less frequently.
What role does Similarweb’s LLM comparison tool play in tracking topical authority? Similarweb’s LLM comparison feature lets you see how different models contribute to brand and category visibility, making it possible to compare how your brand is perceived across ChatGPT, Gemini, Claude, Perplexity, and others in a structured way. This gives you a consistent view of where you stand and where competitors are outperforming you.
How often should I check my brand’s standing in LLMs?
For most brands, a monthly check is a reasonable starting point. For brands in fast-moving categories or those actively trying to improve LLM visibility, more frequent monitoring makes sense. Keep in mind that static models like ChatGPT update less frequently, so changes take longer to show up there compared to retrieval-based models like Perplexity.
Is building topical authority for LLMs worth the investment compared to traditional SEO?
It’s not really an either/or choice, and that’s the good news. The content strategy that builds LLM topical authority (deep coverage, third-party credibility, clear category ownership) also strengthens traditional SEO. The core work overlaps significantly. The main addition is a measurement and strategy layer that specifically accounts for LLM visibility, which is where tools like Similarweb’s GEO features come in.

Related Posts




Why AI Engines Cite UGC Over Brand Content And How To Leverage It For AEO

AI Mentions vs. AI Citations: What’s the Difference and Why It Matters for GEO


Wondering what Similarweb can do for your business?
Give it a try or talk to our insights team — don’t worry, it’s free!