




How Query Reformulation In LLMs Changes Keyword Research Methodology For GEO

Imagine someone on your team typed “best competitive intelligence platform for enterprise marketing teams” into Perplexity.
Before Perplexity retrieved a single document, the LLM decomposed that query into roughly a dozen sub-queries: “what is competitive intelligence software,” “competitive intelligence platforms comparison,” “enterprise marketing analytics tools,” “how to choose a CI platform.”
Each was searched independently, ranked separately, and synthesized into the final answer your prospect sees.
Your content was optimized for the original query. Whether it appears in that answer depends entirely on how well it covers the sub-queries the LLM generated. Queries your audience never typed. Queries you have never tracked.
I have been in SEO for 20 years. I have lived through the keyword stuffing era, the Panda update, the rise of semantic search, and the shift to mobile-first indexing. Each time, the underlying question remained the same: which query should this page rank for?
In my role leading GEO and AEO strategy at Similarweb, I spend a lot of time asking a different question now: which sub-queries will an LLM generate from our audience’s anchor questions, and is our content ecosystem eligible to be cited for each?
That second question is the gap where most SEO teams are silently losing AI visibility. It is structural. According to joint AI Mode referral research from iPullRank and Similarweb, AI search queries average 70 to 80 words, compared to 3 to 4 words in traditional Google search.
The queries are longer and more complex, which means the decomposition is broader and the sub-query surface area is larger.
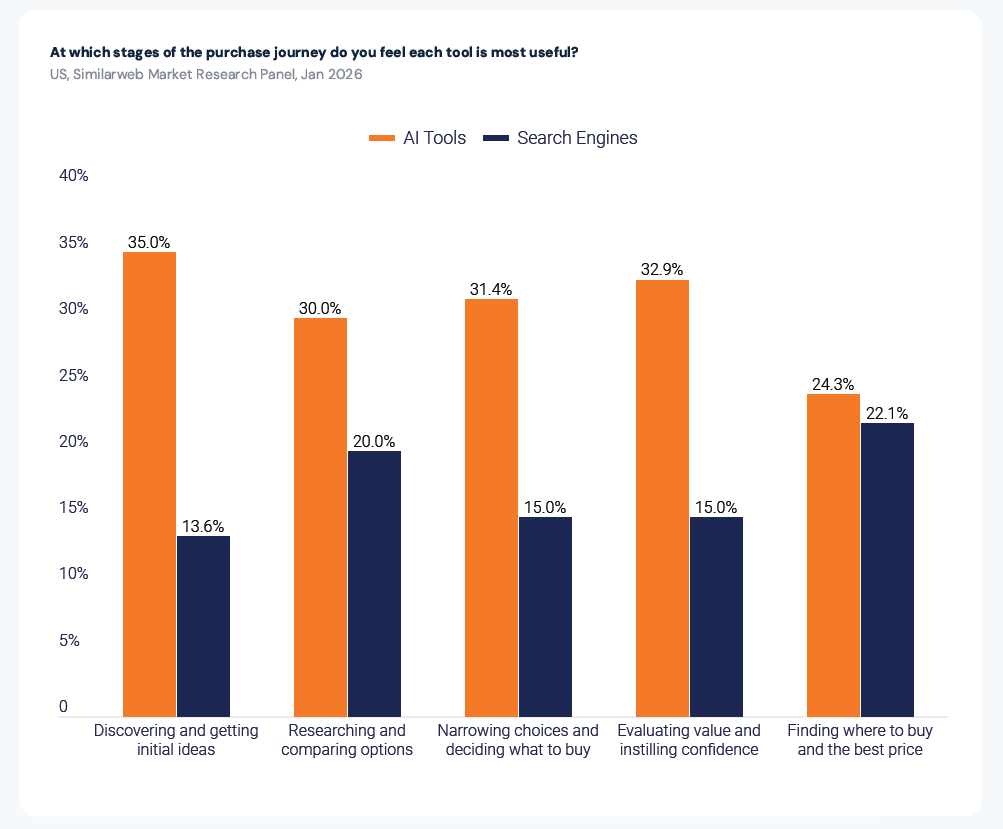
And Similarweb’s 2026 AI Brand Visibility Report confirms the stakes: 35% of consumers use AI tools at the discovery and initial ideas stage of the purchase journey, compared to just 13.6% who use traditional search engines at that same stage. Miss the AI answer, miss the consideration set.
Meanwhile, traditional SEO strategy is still built around optimizing one page for one keyword: a model that captures exactly one slot in a system where every answer draws from multiple independently retrieved sources.
This article is not another explainer on what query fan-out is. Those exist. This is about what you do differently on Monday morning as a result.
I will walk through why the traditional keyword-to-page model structurally fails in LLM search, how the query reformulation pipeline actually works, and most importantly, the revised keyword research methodology I use at Similarweb for GEO, including a working framework and a fan-out mapping template you can copy immediately.
What do LLMs actually do with your “Search query”?
Query reformulation is the process by which an LLM transforms a user’s original input into one or more optimized retrieval queries before fetching any content. The gap between the query a user submits and the queries an LLM actually searches is where keyword strategies fail silently.
The mechanism is documented in academic literature as the “Rewrite-Retrieve-Read” pipeline and commercially in Google’s Thematic Search patent.
In practice, a single user query passes through at least five transformations before any content is retrieved.
- Intent parsing: The LLM classifies what the user is actually trying to accomplish: not the surface-level topic, but the underlying task.
- Query rewriting: The raw input is cleaned, formalized, and disambiguated. Typos corrected, jargon expanded, implicit context made explicit.
- Query fan-out / decomposition: The query branches into 6 to 20 sub-queries, each targeting a different facet of the original intent. Google named this officially in their AI Mode blog post at Google I/O 2025: “AI Mode uses our query fan-out technique, breaking down your question into subtopics and issuing a multitude of queries simultaneously on your behalf.”
- Parallel retrieval: Sub-queries are searched simultaneously across the index. Each sub-query retrieves a separate set of candidate documents.
- Chunk scoring and synthesis: Retrieved passages (not pages) are ranked for relevance to each sub-query and assembled into the final answer. LLMs retrieve at the paragraph level, not the page level. This distinction changes everything about how content should be structured.
How each major platform handles this differently
The fan-out mechanism is consistent across platforms, but the implementation varies across platforms. This matters for content strategy because the sub-query space each platform generates can differ in emphasis.
| Platform | Fan-Out Mechanism | Observable? | Key Characteristic |
| Google AI Mode | Named “query fan-out” (Google I/O 2025) | Yes, shows search steps | Gemini generates parallel themed sub-queries, retrieves 20 to 100 candidates per sub-query |
| Perplexity | Hybrid retrieval: dense vector plus BM25 plus multi-stage ranking | Yes, “Steps” tab | Treats document sections as atomic retrieval units, as stated in their API architecture |
| ChatGPT | Query reformulation is strongly implied by retrieval behavior | Partially | 31% of prompts trigger web search across 8,500+ analyzed prompts (Nectiv, Oct 2025). OpenAI has not published architecture details |
| Microsoft Copilot | Iterative grounding loop, not pure parallel fan-out | Limited | Sequential: each result informs the next query, creating a grounding chain rather than a parallel burst |
My practical takeaway from this data: do not assume the same content strategy works the same way across all AI platforms.
Content that covers a topic in a complete, atomic manner is universally more retrievable. But the specific sub-query space each platform generates for the same anchor query can diverge.
The instability problem that changes everything
Here is the part most query fan-out explainers skip: the sub-queries LLMs generate are non-deterministic. Only 27% of fan-out sub-queries remain consistent across different searches of the same query, and 66% appear only once.
That is not a bug in the system. That is the architecture. LLMs are stochastic by design, and their fan-out behavior is further shaped by user context, session history, platform, and model version.
Two different users asking the same question may trigger different sub-query decompositions and receive different answers.
The implication for keyword research is significant: the specific sub-queries you would find if you reverse-engineered one LLM’s response today are not the sub-queries that will appear tomorrow.
Optimizing for a fixed list of specific sub-queries means chasing a moving target. Optimizing for comprehensive semantic coverage of a topic space, so that your content is eligible regardless of which specific sub-queries the LLM generates, is the only durable approach.
Why “One page, one keyword” is structurally broken for LLM search
Traditional keyword-to-page mapping assumes your content competes for the query a user types. In LLM search, that query is immediately decomposed into 6 to 20 sub-queries before any content is retrieved.
A page optimized for a single keyword is eligible for exactly one sub-query slot in a system where each slot cites only 2-7 sources.
The math is unforgiving.
In traditional Google search, a number-one ranking makes you visible to everyone searching that term.
In LLM search, you need to be citation-eligible across multiple sub-queries simultaneously, because the LLM is pulling from several independent retrieval operations to build a single answer.
A page that covers only the seed query might be completely absent from the final response, even though it is technically relevant.
Let me show you how this plays out with real data. I pulled “query fan out” from Similarweb’s keyword intelligence. It receives 2,764 monthly searches in the US as of January 2026, with a keyword difficulty of 20 and essentially zero paid competition.
That same keyword has a 67% zero-click rate, meaning more than half of all searches for it are answered directly in the SERP by AI, without anyone clicking through to any website. Visibility for this query is no longer primarily a ranking problem. It is a citation problem.
Meanwhile, the parent keyword “generative engine optimization” has a difficulty of 85 with competition of 66.
The semantic space most SEOs are fighting to enter is already saturated. The sub-query spaces fanning out from these topics (the specific facets, comparisons, how-tos, and use cases) have almost no competition.
That is where the citation opportunity lives.
What traditional keyword research gets wrong (And gets right)
Declaring traditional keyword research dead is lazy. Traditional keyword data (volume, difficulty, intent classification, CPC) is still useful. It just has a different job now.
In a GEO-adapted workflow, I use traditional keyword data to answer the prioritization question: which sub-queries in my fan-out space are worth dedicated content versus section-level coverage?
A sub-query with 500 searches per month warrants its own article. One with 50 searches might get a 200-word subsection. Traditional data tells you which is which.
What traditional keyword research cannot tell you: which sub-queries LLMs are generating, which content chunks are being retrieved for which sub-queries, how visible your brand is in AI-generated answers, or whether your content architecture supports chunk-level retrieval.
Those require a different toolkit and a different mental model:
| Dimension | Traditional SEO Research | AEO/GEO-Adapted Research |
| Primary planning unit | Single keyword | Topic plus full intent cluster |
| Research goal | Find rank-worthy terms | Map the complete fan-out space |
| Volume metric | Monthly search volume | Fan-out surface area coverage |
| Optimization target | One keyword per page | Semantic coverage across the sub-query cluster |
| Success metric | Rank position in Google | AI citation frequency plus share of voice |
| Content structure driver | Keyword density and placement | Chunk-level retrievability |
| Failure mode | Algorithm update drops rankings | Sub-query coverage gaps create invisible blind spots |
The FAN methodology: A revised keyword research workflow for AEO and GEO
I call this the FAN Methodology: a three-component framework for restructuring keyword research around the reality of LLM query decomposition. It does not replace traditional keyword research. It reframes what keyword research is for.
F: Fan-out Mapping: Identify and document the full sub-query space for your target topics before creating a single piece of content.
A: Authority-Signal Alignment: Ensure every content unit contains the data signals that GEO research confirms drive citation selection.
N: Node Architecture: Structure content so each section is independently retrievable as an atomic, citation-eligible chunk.
Here is how I execute each component in practice.
F: Fan-out mapping
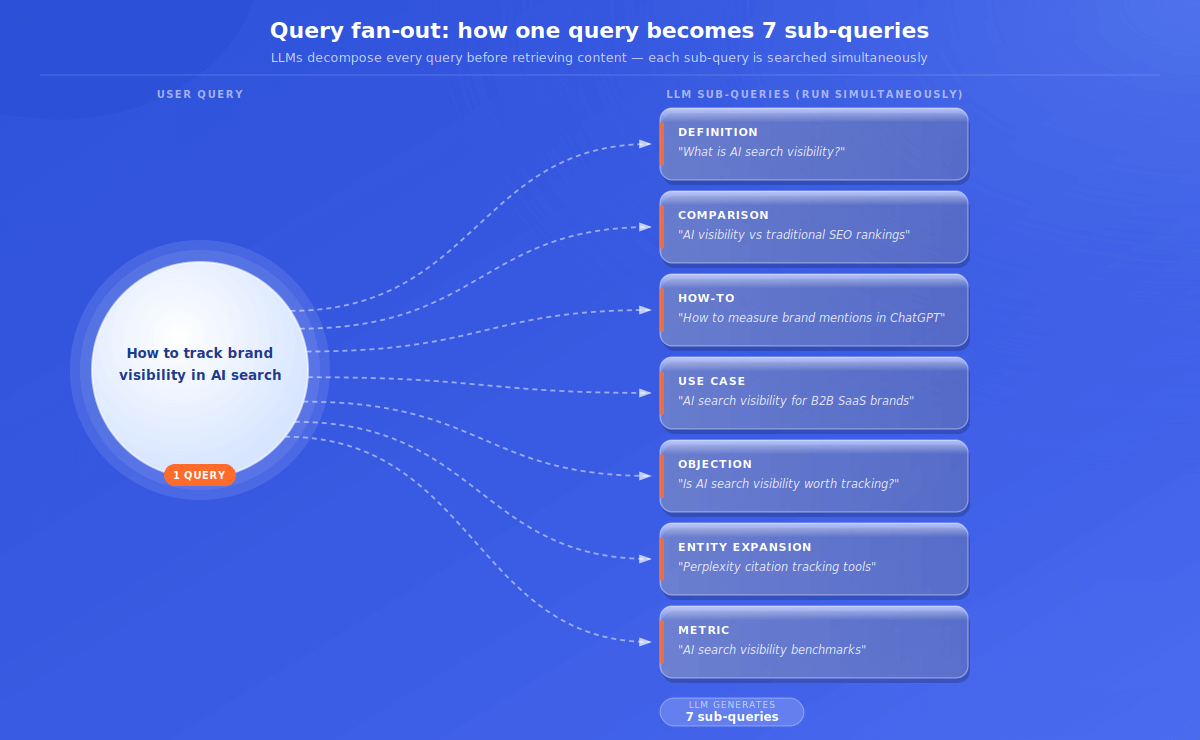
Fan-out mapping is the new seed keyword research. Instead of starting with a short-tail keyword and expanding outward, I start with the conversational anchor query my audience actually asks an AI engine (typically 15 to 25 words) and decompose it into its sub-query space.
Finding anchor queries
I get these from three places: sales and customer success teams (what questions prospects ask in real conversations, not what they search for), support tickets and onboarding questions (which tend to be in natural-language question format), and direct experimentation by prompting AI engines on our core topics and examining the search steps they generate.
For Similarweb content, “how do I track my brand’s visibility in AI-generated search answers” is an anchor query. “AI search visibility” is a seed keyword.
The anchor query is how people talk to AI engines.
The seed keyword is how SEOs have historically thought about content strategy. Generative Engine Optimization requires thinking in anchor queries first.
Decomposing the fan-out space
For each anchor query, I map out the probable sub-query types the LLM will generate. Every anchor query fans out across at least seven sub-query categories:
| Sub-Query Type | Example (“how to track brand visibility in AI search”) | Covered? |
| Definition | “What is AI search visibility?” | Y / N |
| Comparison | “AI search visibility vs traditional SEO rankings” | Y / N |
| How-to | “How to measure brand mentions in ChatGPT.” | Y / N |
| Use case | “AI search visibility for B2B SaaS brands” | Y / N |
| Objection | “Is AI search visibility worth tracking?” | Y / N |
| Entity expansion | “Perplexity citation tracking tools” | Y / N |
| Metric | “AI search visibility benchmarks” | Y / N |
This is what I call a Fan-Out Coverage Audit. Gaps in the “Covered?” column are content briefs waiting to be written.
A: Authority-signal alignment
The foundational GEO research from Princeton, Georgia Tech, and IIT Delhi tested multiple optimization strategies against LLM citation rates using the GEO-Bench benchmark.
The finding that permanently changed how I brief content: Statistics Addition (modifying content to include quantitative data instead of qualitative description) improved visibility by up to 41%. Keyword stuffing performed below the unoptimized baseline.
Let that land.
Adding statistics improves citation rates by 41%. Adding keywords makes it worse.
This means every major section of every piece of GEO-optimized content needs at a minimum one quantified claim you can own. For Similarweb content, that is, keyword volume data, AI-referred traffic trends, zero-click rates, or citation frequency from the Similarweb AI Tracker.
For your content, it is whatever primary data you have that no one else can cite.
The same research found that Quotation Addition (adding credible citations and references from authoritative sources) improved visibility by 28%. Your external linking strategy is now also a GEO signal.
Citing the original Princeton paper, the Google patent, the official Google blog post: these are not just good attribution. They are citation-worthiness signals.
Research from AutoGEO further confirmed that Gemini, GPT, and Claude share 78-84% of content preference rules. This means the signals that make content citation-worthy are largely consistent across platforms.
I am not building separate strategies for each engine. I am building one well-structured, data-rich content ecosystem.
N: Node architecture
LLMs do not retrieve pages. They retrieve passages. A 3,000-word article is not the unit of retrieval. Individual paragraphs and sections are. This means content architecture is itself a keyword research output.
Node architecture means structuring content so every significant section is a self-contained, independently retrievable unit: an atomic chunk that answers one sub-query completely without requiring context from earlier in the article.
Three rules I follow for node architecture:
Rule 1: Every H2 opens with a standalone direct answer
The first 30 to 60 words of every H2 section must answer that section’s question completely, as if it is the only content a reader (or an LLM) will see. No, “as I discussed above.” No pronoun references to previous sections.
Rule 2: Definitions are always explicit
“Query reformulation is the process by which an LLM transforms a user’s original input into retrieval queries,” not “query reformulation, which most SEOs have heard about by now.” LLMs match definitions. Implied definitions are invisible to retrieval.
Rule 3: Statistics carry full context
Every quantified claim needs: a number, a population, an action, a timeframe, and a source. “27% of fan-out sub-queries remain consistent across different searches of the same query” is citation-eligible. “Fan-out is inconsistent” is not.
Step-by-step: The GEO keyword research workflow in practice
Here is FAN applied as an end-to-end process. I use this to extend (not replace) the traditional keyword research workflow I wrote about in an earlier Similarweb guide.
- Define your anchor queries: Collect 5 to 10 conversational questions your audience asks AI engines about your core topics. These should be 15 to 25 words and phrased as questions. Sources: sales calls, support tickets, community forums, and direct testing of the AI engine.
- Run your Fan-Out Coverage Audit: For each anchor query, map the seven sub-query types. Check each against your existing content. Document gaps.
- Run traditional keyword research on the gap list: Take every uncovered sub-query and validate with Similarweb keyword intelligence. Volume and difficulty determine whether a gap becomes a standalone article or a section within an existing piece.
- Brief content to FAN standards: Every content brief should specify: anchor query, fan-out map, required statistics with sources, node architecture requirements, and internal links. The keyword mapping framework I use at Similarweb remains relevant here. The difference is that I am mapping sub-queries to content units, not just keywords to pages.
- Audit existing content for fan-out coverage: I recommend pulling your top 20 traffic-driving pages and running them through the fan-out mapping exercise. How many sub-query types does each page cover? Pages addressing only one sub-query type are citation-vulnerable: they can be completely omitted from LLM answers on their own topic despite good traditional rankings.
The GEO keyword brief template
Here is the template I use for any piece of GEO-optimized content:
You can copy it for free
The pro approach: Automate your GEO keyword research workflow
Now that we have broken down the research process step by step, it’s time to take it to the next level by automating it.
If you want to execute this entire workflow in minutes, you can do what I did:
- I connected the Similarweb MCP server to Claude,
- I created a skill that follows the framework and retrieves the relevant data
- Then I loaded it with Similarweb’s brand guidelines and the GEO brief template.
That’s it.
An easy, repeatable process for content brief creation that considers SEO but also AEO and GEO needs.
What to stop measuring, and what to start
The measurement shift follows directly from the methodology shift. If you are still reporting primarily on keyword rank positions, you are measuring the wrong game.
Stop treating keyword rank as your primary GEO KPI.
SEOClarity analyzed ChatGPT’s top 1,000 cited URLs over one week in November 2025 and found that 25% of them had zero organic visibility on Google.
According to data from Status Labs’ citation research, only 12% of URLs cited by ChatGPT, Perplexity, and Copilot rank in Google’s top 10. Rank is still the entry fee (if you are not indexed and discoverable, you cannot be retrieved), but it is no longer the scorecard.
Stop tracking keyword density. Keyword stuffing performs below the unoptimized baseline. Density is not a signal LLMs reward.
Here is the measurement stack that actually maps to LLM visibility:
| KPI | What It Measures | Tool |
| AI citation frequency | How often are you cited across a tracked query cluster in LLM responses | Similarweb AI Search Intelligence |
| Brand mention rate | Brand mentioned in AI responses, with or without a link | Similarweb AI Search Intelligence |
| Fan-out coverage score | Percentage of sub-query space where you have indexed, retrievable content | Audit using the GEO brief template above |
| SoV in AI answers | Your citations vs. competitors across tracked topic clusters | Similarweb AI Search Intelligence |
| Sub-query rank | Are you in the top 20 for the specific sub-queries LLMs fan out to? | Similarweb Search Intelligence |
| Zero-click rate | The percentage of searches answered in SERP without a click shows where GEO & AEO visibility matters most | Similarweb Search Intelligence |
The zero-click metric deserves special attention. “Query fan out” has a 67% zero-click rate as of January 2026, according to my Similarweb keyword data.
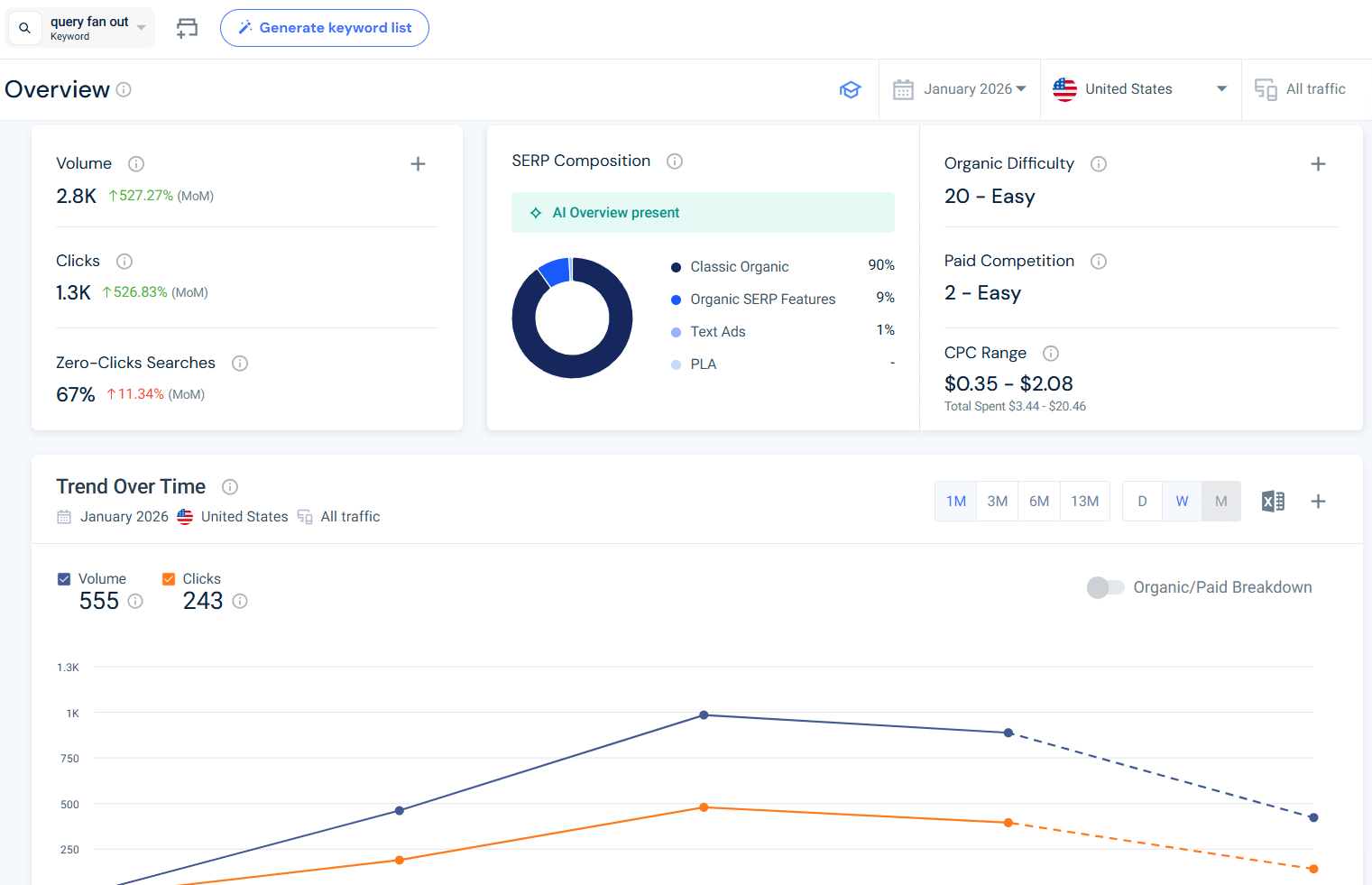
More than half of the people searching this term are getting their answer without visiting any website. For those searches, being cited in the AI Overview or Perplexity response is the visibility. Rank tracking alone misses it completely.
The keyword brief did not die, but got a promotion.
Traditional keyword research answered one question: what exact phrase should this page rank for?
GEO-adapted keyword research answers a fundamentally different question: what is the complete semantic space, across all the sub-queries that will fan out from our audience’s AI search behavior, where our content needs to exist and be citation-eligible?
The second question is harder to answer. It requires mapping anchor queries rather than seed keywords, auditing fan-out coverage rather than keyword density, and measuring AI citation frequency rather than rank position.
The workflow has become more complex, the template is longer, and the thinking is less mechanical.
But the window is open right now. The practitioners who understand that AI engine visibility is won in the sub-query space, not in the main keyword, will establish topical authority in LLMs before the rest of the industry catches up.
Traditional SEO is still the entry point. You need to be indexed and visible for the sub-queries LLMs fan out to. But ranking is no longer the full game.
The full game is building a content ecosystem comprehensive enough that, regardless of which sub-queries an LLM generates from your audience’s anchor queries, your content is citation-eligible for most of them.
That is not a minor update to your keyword brief. That is a new job description for keyword research itself.
FAQ
What is query fan-out in LLM search?
Query fan-out is the process by which an LLM-powered search engine decomposes a single user query into multiple sub-queries before retrieving any content. Google officially named this mechanism at Google I/O 2025. A typical query fans out into 6 to 20 sub-queries, each searched independently, with results synthesized into a single AI-generated answer.
How does query reformulation differ from query fan-out?
Query reformulation is the broader pipeline: the LLM cleans, clarifies, and rewrites a user’s raw input before retrieval. Query fan-out is one specific step within that pipeline, where the rewritten query branches into multiple parallel sub-queries rather than remaining a single search. Most LLM search systems do both, sequentially.
Does traditional keyword research still matter for GEO?
Yes, but its role has shifted from primary target to prioritization tool. Traditional keyword data (volume, difficulty, intent) answers which sub-queries in your fan-out space warrant a standalone article versus section-level coverage. A sub-query at 500 monthly searches needs its own page, and one at 50 searches gets a 200-word subsection. What traditional research cannot tell you is which sub-queries LLMs are generating or how retrievable your content is at the chunk level.
Why does keyword stuffing hurt GEO performance?
Keyword stuffing performs below the unoptimised baseline in LLM engines, according to the GEO-Bench study by researchers at Princeton, Georgia Tech, and IIT Delhi. LLMs reward semantic relevance, structural clarity, and quantified data, not keyword repetition. The same study found that adding statistics to content improved LLM citation rates by up to 41%, while stuffing actively degraded visibility.
How do I find the sub-queries LLMs generate for my target topics?
Three practical methods I use:
- Gemini’s API returns fanout_queries explicitly as a parameter
- Perplexity’s “Steps” tab shows the sub-queries it generates during a search
- Google AI Mode’s visible search steps show Gemini’s sub-queries in real time.
For systematic fan-out mapping at scale across topic clusters, Similarweb’s AI SEO Strategist agent can help automate this process.
Does this approach work equally across ChatGPT, Perplexity, Claude, and Google AI Mode?
Largely yes. The AutoGEO paper found that Gemini, GPT, and Claude share 78 to 84% of content preference rules, meaning citation-worthiness signals are substantially consistent across platforms. The differences are in degree: Perplexity weights authoritative citations heavily, Google AI Mode leverages its Knowledge Graph for entity relationships, and ChatGPT’s search mode triggers web retrieval for approximately 31% of prompts. The FAN methodology’s core principles, comprehensive fan-out coverage, and data-dense atomic chunks apply across all four.
What is the difference between query fan-out and topic clustering?
Query fan-out is what LLMs do: decomposing a single user query into multiple sub-queries at retrieval time. Topic clustering is what you do: organizing your content into hub pages and supporting articles that cover a subject comprehensively. Topic clustering is your content strategy response to the reality of query fan-out. When you build topic clusters that map to the seven sub-query types (Definition, Comparison, How-to, Use case, Objection, Entity expansion, Metric), your content becomes retrievable across the full fan-out space.

Related Posts



What Is AI Share of Voice? The Brand Mention Share Metric You’re Probably Missing




Wondering what Similarweb can do for your business?
Give it a try or talk to our insights team — don’t worry, it’s free!