




10 Ways To Use AI For Keyword Research

Manual keyword research is slow, incomplete, and backward-looking. You start with a seed keyword, expand through a database, filter by difficulty, check competitor coverage, cluster by intent, and repeat, for every topic, every quarter, every time the content plan changes. The process works. It just takes forever.
AI compresses that workflow significantly. LLM-assisted ideation generates a full keyword cluster in minutes. Validation against real search data takes seconds per term with the right tooling. Intent classification that once required manual judgment on hundreds of rows runs in one prompt.
Clustering, which used to be a spreadsheet exercise, becomes a structured output you can feed directly into a content brief.
This guide gives you ten distinct ways to use AI for keyword research with Similarweb, a six-step validation workflow, and a breakdown of how to use AI specifically for trend detection and zero-search-volume discovery, the two areas where traditional databases fall furthest behind.
What is AI keyword research?

AI keyword research is the practice of using large language models and AI-powered tools to discover, cluster, classify, and prioritize keywords for SEO.
Unlike traditional keyword databases that measure historical search demand, AI tools infer user intent, surface emerging topics before they appear in volume data, and help identify zero-search-volume queries driving real conversions right now.
The key distinction is where the intelligence comes from. A traditional keyword tool looks up what people have searched. An AI generative tool reasons about what people are likely to search, how those searches cluster by topic and intent, and what questions users are asking AI engines directly rather than Google.
Google’s own research confirms that 15% of searches performed on Google every day are new queries that have never been seen before. AI tools can surface that 15% by reasoning about user intent rather than counting historical volume.
Paired with Similarweb’s fresh keyword data for validation, that combination is both faster and more comprehensive than any traditional keyword research process alone.
AI keyword research vs traditional keyword research
AI keyword research and traditional keyword research are not competing approaches. One looks backward, the other looks forward, and you need both. The mistake is treating a traditional keyword database as a complete system.
Here is where the two approaches diverge:
| Dimension | Traditional keyword research | AI keyword research |
| Data source | Historical search volume databases | LLM reasoning + search data validation |
| New query detection | Only shows queries with prior search history | Surfaces zero-search-volume questions from real intent |
| Intent classification | Rule-based or volume-based | Semantic and context-aware |
| Keyword clustering | Manual grouping or basic similarity matching | LLM-driven semantic clustering in seconds |
| Speed for ideation | Slow: requires seed inputs and iteration | Fast: generates clusters from a single prompt |
| Keyword trends | Lagging indicator (based on past data) | Leading indicator (pattern recognition) |
| AI search coverage | No visibility into what LLMs are answering | Surfaces the questions AI engines are fielding |
| Validation | Built-in (volume is the data) | Requires secondary validation with real data |
| Best for | Confirming and quantifying demand | Discovering and structuring demand before it peaks |
The bottom line: AI keyword research without Similarweb validation is guesswork.
The ten methods below are used in combination.
10 ways to use AI for keyword research with Similarweb
Way 1: AI ideation and Similarweb validation
This is the baseline workflow. Use any capable LLM to generate keyword ideas from a seed topic or anchor query, then validate every suggestion using Similarweb MCP or in the Keyword Generator for volume, keyword difficulty, zero-click rate, and intent distribution before any content decision is made.
The Similarweb validation step is not optional. LLMs do not query live search data. They reason about what topics are relevant based on training patterns, not what has measurable current demand. A term can appear throughout an LLM’s training corpus without generating a single monthly search.
Similarweb closes that gap: every human and LLM-generated keyword gets a volume, difficulty, zero-click rate, and trend check before it enters a brief.
Way 2: Competitor keyword discovery
Ask an LLM to analyze your competitors’ content landscape: which topics are they covering systematically, which questions would their audience ask, and which angles are they likely prioritizing based on their positioning?
Then, validate those suggestions in Similarweb by analyzing competitors’ actual keyword traffic, their top-performing landing pages, and the SERP player data for the highest-value queries.
Similarweb’s SERP players feature shows which competitors are winning specific queries and how their traffic share has shifted over time. The keyword gap tool confirms which validated terms competitors rank for that your content is not capturing.
Pro tip: Connect Similarweb MCP to your favorite AI to do this step. The validation and analysis will be built in. Here’s a fresh example of how this looks for openai.com:
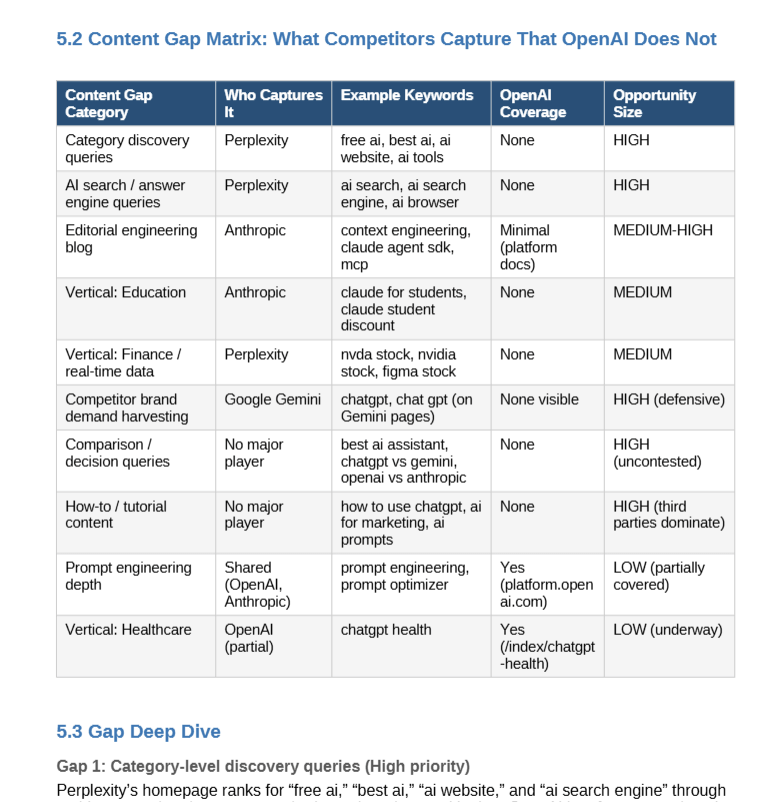
Way 3: Keyword clustering
Take a large raw keyword list from the keyword generator, list, or tracker, and ask an LLM to group it into semantic clusters by topic and sub-topic. A well-structured prompt returns clusters named, sized, and annotated with the shared intent for each group. What used to be a multi-hour spreadsheet exercise with manual grouping takes minutes.
Once clusters are formed, validate each cluster with Similarweb MCP to confirm the aggregate search volume and the average keyword difficulty for each group. This tells you which clusters represent real content opportunities versus which are topically coherent but commercially thin.
Similarweb’s keyword data lets you track cluster-level traffic share over time, so you can monitor whether your coverage of each cluster is translating into rankings.
Example LLM prompt for keyword clustering (without MCP):
“I have [X] keywords related to [topic]. Group them into semantic clusters of 5–10 keywords each. For each cluster: (1) name it, (2) describe the shared user intent, (3) suggest a primary keyword and 3 supporting terms. My audience is [description]. Output as a structured table.”
Way 4: Intent classification
Feed your keyword list to an LLM and ask it to classify each term by search intent: informational, commercial, transactional, or navigational. LLMs are better at this than rule-based classification systems because they interpret the semantic meaning of a query rather than pattern-match on keyword signals.
Cross-reference the LLM’s intent classification against Similarweb’s intent distribution data for each keyword. Similarweb shows the split between informational and transactional intent for a given term, which is a reliable signal check on the LLM’s output.
Mismatched classifications, where the LLM says transactional but Similarweb data shows 80% informational, are content strategy errors waiting to happen. Catching them at the keyword stage is the fix.
Way 5: Keyword trend detection
Ask an LLM to identify emerging topics and questions in your niche that are likely to grow in search demand.
- Which concepts are spilling from specialist communities into mainstream awareness?
- Which product categories, regulations, or platform shifts are likely to generate new query clusters in the next 3 to 6 months?
Cross-reference those suggestions with Similarweb’s keyword trend data, which shows month-over-month and year-over-year volume changes per query. Terms the model flags as emerging that are simultaneously showing rising Similarweb volume data are your highest-priority content investments.
The combination of LLM pattern recognition and validated Similarweb trend data surfaces keywords during the window where you can still rank before competition intensifies.
Way 6: Zero-search-volume keyword discovery
Traditional keyword databases only surface queries with measurable historical volume.
An LLM can go further by generating questions from the contexts where real user language lives: customer support logs, product reviews, sales call recordings, community forums, and onboarding conversations.
These are the questions users are asking daily, many of which have never accumulated search volume but carry strong commercial intent.
After generating a zero-search-volume candidate list, use Similarweb to monitor whether any term has started to accumulate volume, which signals early demand.
A keyword moving from zero to 50 monthly searches is often more valuable than a 5,000-volume keyword with KD 90, because you can rank for it now before competition arrives.
Way 7: Keyword gap analysis
Use an LLM to compare your content coverage against competitors by analyzing their URL structures, site architectures, and content patterns.
- Which topics are they covering systematically that your content is missing?
- Where do their topic clusters have depth that you have not matched?
Then, validate the identified gaps with Similarweb MCP or use the keyword gap analysis feature to confirm which gaps have search volume that your existing content is not capturing. The LLM surfaces candidates based on competitive content intelligence. Similarweb confirms which candidates have actual demand.
Way 8: GEO keyword research using the FAN methodology
For AI search optimization, keyword research extends beyond volume and difficulty into query fan-out mapping. When an LLM receives a user question, it decomposes it into multiple sub-queries and retrieves content for each independently. The FAN methodology is a structured framework for identifying those sub-queries.

It starts with an anchor query: a 15 to 25-word conversational question that reflects how your target audience would phrase the topic to ChatGPT or Perplexity. From that anchor query, the methodology maps seven sub-query types LLMs typically generate: Definition, Comparison, How-to, Use case, Objection, Entity expansion, and Metric.
Each sub-query type is then validated in Similarweb for volume, keyword difficulty, and zero-click rate.
The zero-click rate is particularly important here. A sub-query with a 60% zero-click rate is not primarily a traffic opportunity; it is a citation opportunity, and the content briefed against it should be structured for AI retrieval rather than a standard click-through experience.
As I pointed out in my GEO keyword research guide, only 27% of fan-out sub-queries remain consistent across repeated searches of the same query. This is why optimizing for comprehensive semantic coverage, rather than a fixed list of specific sub-queries, is the only durable GEO strategy.
Way 9: Automated pipeline with Claude and the Similarweb MCP
The Similarweb MCP (Model Context Protocol) integration connects Claude directly to Similarweb’s keyword data.
Once set up, you can load a keyword research skill, provide a single anchor query, and have Claude automatically map all fan-out sub-queries, validate each against live Similarweb keyword data, classify by intent, check for coverage gaps against your existing content, and output a pre-populated content brief.
In our own SEO and content team testing, running the full FAN methodology manually takes roughly 3.5 hours per anchor query, including sub-query mapping, Similarweb validation, intent classification, and brief population.
The automated Claude plus Similarweb MCP pipeline completes the same process in under 20 minutes. For teams managing multiple topic clusters simultaneously, that difference compounds quickly.
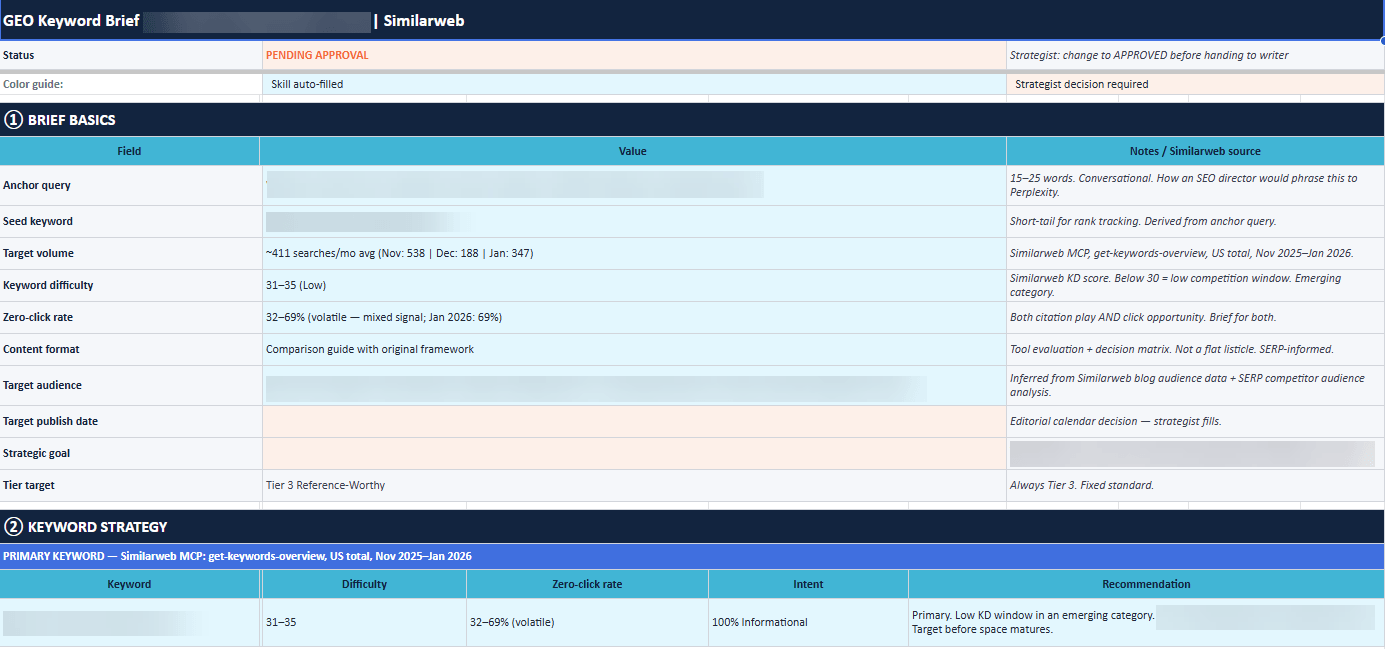
The setup takes two minutes and requires no code. Full instructions are in the Similarweb MCP keyword research automation guide.
Way 10: Similarweb AI SEO Strategy Agent
The previous nine methods all involve combining an LLM with Similarweb data through a multi-step process. The Similarweb AI SEO Strategy Agent collapses that process into a single workflow built directly into the Similarweb platform.
No external LLM, no manual validation steps, no prompt engineering required.

The input is a keyword list and a domain. The agent analyzes the competitive landscape using Similarweb’s full dataset, clusters keywords into subtopics by intent and funnel stage, ranks each cluster by opportunity based on keyword gaps and competitive difficulty, and produces a prioritized content roadmap.
It also analyzes the top-ranking pages for each cluster to recommend content formats, on-page structure, and off-site opportunities such as publisher partnerships and backlink targets.
The distinction from the MCP pipeline in Way 9 is the user profile. Way 9 is built for teams running high-volume, customizable keyword research workflows who want full control over each validation step.
The AI SEO Strategy Agent is built for SEO and content managers who need a complete, data-backed content plan from a keyword list in a single session, with no setup and no context-switching between tools.
The output is exportable as a PDF and structured for direct use in content briefs and strategy meetings. A full walkthrough of how to use the agent is in the SEO Strategist Agent guide.
What are the benefits of AI for keyword research?
Using AI for keyword research delivers three distinct improvements over a purely database-driven approach: speed, coverage, and structure.
- Speed: A traditional keyword research process (seed expansion, filtering, clustering, competitor analysis) takes hours per topic cluster when done manually. AI handles the ideation, clustering, and classification layers in minutes, using Similarweb MCP for validation and enrichment.
- Coverage: AI surfaces emerging topics before they peak in volume data, zero-search-volume queries with real commercial intent, and the specific questions users are asking AI engines that only appear in Similarweb’s fresh keyword database.
- Structure: The output of an AI keyword research process is not just a list of keywords. Gen AI engines can give you a complete content architecture: which topics are pillars, which are supporting nodes, which should be FAQ blocks rather than standalone articles. Validating AI recommendations with Similarweb data grounds your content plan to measurable results.
Princeton’s GEO-Bench study found that adding statistics to content improves LLM citation rates by up to 40% compared to baseline. Structure and data-density decisions made at the keyword research stage determine whether that improvement is achievable in practice.
How to do AI keyword research: a 6-step workflow
AI keyword research produces the best results when run as a structured workflow rather than a free-form brainstorm. This six-step process combines LLM ideation with Similarweb validation at each stage.
Step 1: Define your anchor query
Start with an anchor query: a 15–25 word conversational question that reflects how your target audience would phrase the topic to ChatGPT or Perplexity. This is your ideation input, not your final keyword. It is the input that drives AI ideation across all ten methods above.
A strong anchor query names the outcome, the context, and the level of specificity. “How do I use AI to find high-intent keywords for my SEO strategy without relying on tools with stale database data?” is more productive than “AI keyword research.”
Step 2: Generate and cluster your keyword list
Feed your anchor query to an LLM and ask it to generate 20 to 30 keyword ideas across different intents, then group them into semantic clusters with a named theme for each cluster. Include in your prompt: your audience’s level of expertise, the product or service context, and any content format constraints.
The clustering output from this step maps directly to your content architecture: each cluster typically corresponds to a pillar article, a supporting post, or a FAQ section.
Step 3: Classify intent and validate in Similarweb
For each LLM-generated keyword, record the intent classification from the model, then cross-reference against Similarweb’s intent distribution data. Then validate every term: monthly search volume, keyword difficulty, zero-click rate, and year-over-year trend.
Cut anything with no measurable volume unless it serves a specific zero-volume strategy. Flag anything with a zero-click rate above 60% as a citation play. Flag any intent mismatch between LLM output and Similarweb data: these are your highest-risk content planning errors.
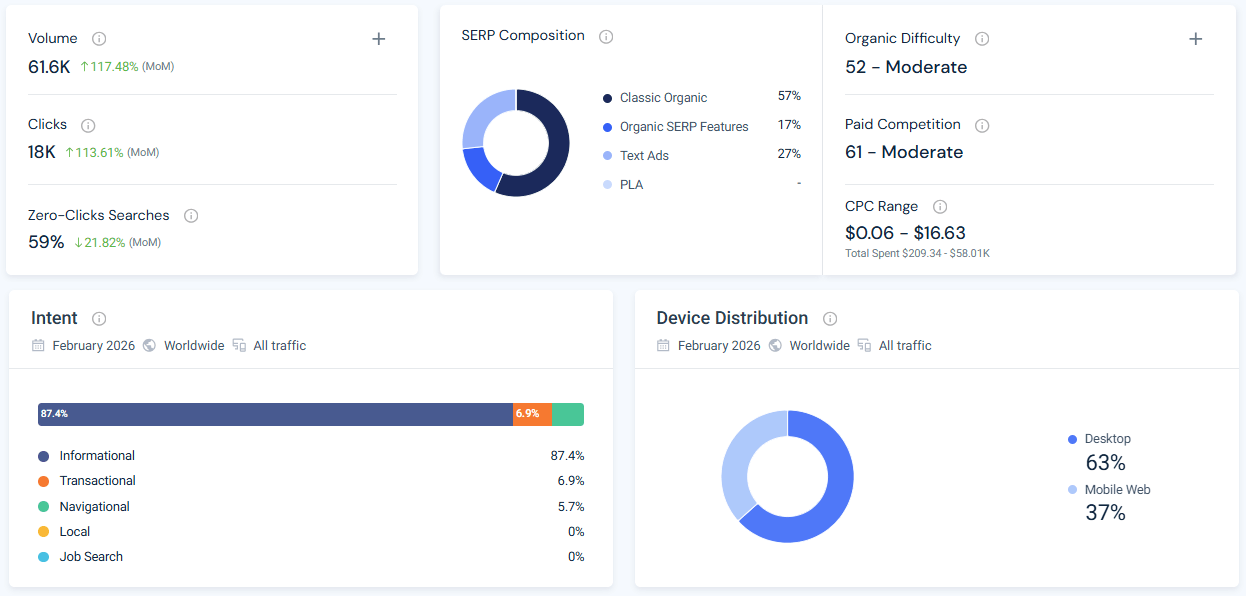
Step 4: Check competitor keyword coverage
Use Similarweb to analyze which validated keywords are already driving traffic to competitors. The SERP players feature shows who is winning specific queries and how the traffic share has shifted over time.
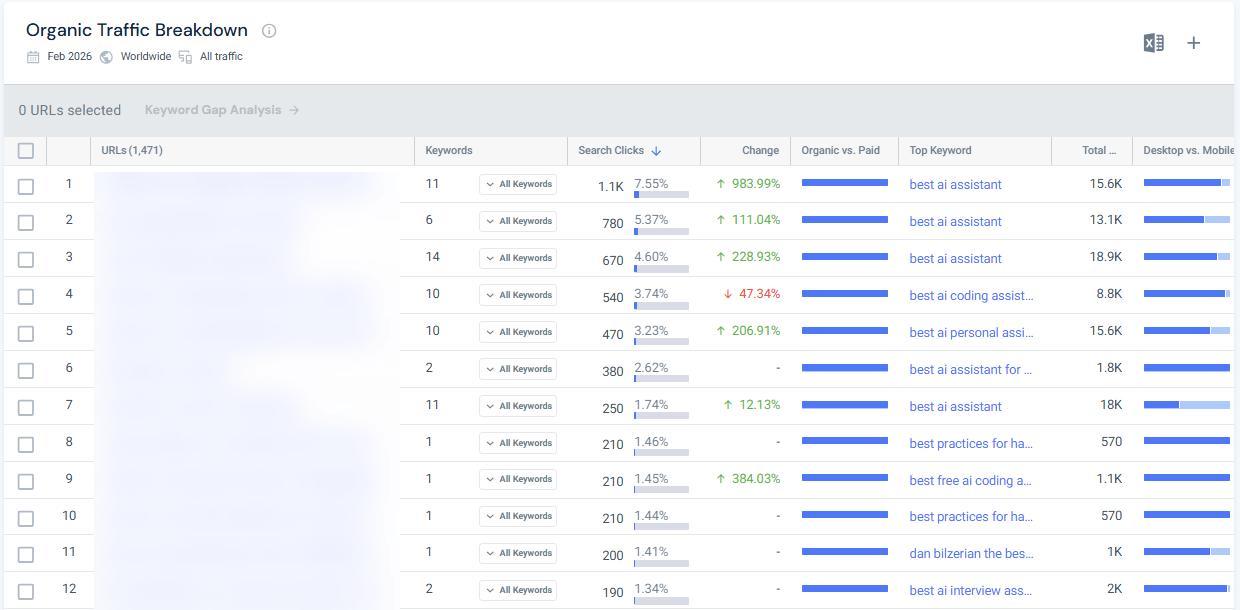
The keyword gap tool identifies which validated terms competitors rank for that your content is not capturing.
Step 5: Identify trending and zero-volume terms
From your validated list, identify which terms are trending upward in Similarweb’s trend view. Cross-reference with any emerging terms the LLM flagged in Step 2. Terms showing rising Similarweb volume that the model flagged early are your priority content investments.
Separately, check your zero-search-volume candidates in Similarweb for any early volume signal. A single month of 20 to 30 searches on a previously zero-volume term is an actionable early indicator.
Step 6: Build your keyword map and prioritize
Organize your validated, intent-classified, trend-checked keyword list into a content map:
- Primary keyword per article (one per page, clearly defined)
- Supporting secondary keywords (3 to 6 per article)
- Cluster assignment (which pillar does this support?)
- Intent flag (traffic play vs. citation play)
- Internal link anchor targets
Save this map in Similarweb’s keyword lists feature to track traffic share over time against your target keywords.

Prioritizing keyword research execution using page traffic data
Keyword research produces a list of opportunities. Page traffic data tells you which ones to execute first. Pulling real traffic metrics for your existing pages via the Similarweb MCP turns a flat prioritized list into a tiered execution plan grounded in actual performance, not assumed potential.
After completing Step 6, you have a validated keyword map: clusters confirmed by Similarweb data, intent-classified, gap-checked against competitors, and flagged for traffic versus citation plays. The next problem is volume.
A thorough keyword research pass for a mature content site can uncover dozens of opportunities at once. Without a prioritization layer, execution defaults to whoever shouts loudest in the planning meeting.
The Similarweb MCP resolves this by pulling live traffic data directly into the prioritization workflow. Using the get-keywords-seo-overview and get-websites-traffic-and-engagement endpoints, you can query actual monthly visit data for your existing pages alongside keyword-level traffic share.
That turns abstract keyword opportunity scores into concrete decisions about where to invest writing hours first.
Pro tip: Create skills and workflows with Similarweb MCP already embedded in the process to use all available datapoints when you need them.

The four execution tiers
Tier 1: High-traffic pages, under-optimized clusters
These are your fastest wins. An existing page is already attracting visits but does not yet cover the full keyword cluster your research identified. Pull the page’s current keyword traffic in Similarweb MCP, compare against the validated cluster map, and brief on an optimization pass rather than a new article. The page has authority; it just needs broader coverage.
Tier 2: Competitor-traffic gaps with no current page.
The keyword gap analysis in Step 4 identified queries where competitors are capturing traffic you are not. Pull competitor traffic data for those pages via the Similarweb MCP to confirm which gaps represent the highest volume you are currently surrendering. These become your new content priorities, ordered by web traffic delta.
Tier 3: Low-traffic pages targeting high-value keywords.
These are refresh candidates. Pull page-level traffic data from Similarweb MCP and cross-reference against keyword difficulty and current ranking position. A page targeting a KD 70+ keyword with under 100 monthly visits is structurally underperforming. Prioritize these for full rewrites before launching new content in the same cluster.
Tier 4: Zero-traffic topics with no existing coverage.
New content investments. These go last unless the keyword data shows exceptional trend momentum or the cluster is strategically critical to a product launch. Confirm volume trajectory in Similarweb before committing editorial resources.
Running the prioritization in the Similarweb MCP
The workflow takes one Claude prompt once the MCP is connected. Provide your domain, the URLs of your top existing pages in each target cluster, and the list of validated keyword opportunities from Step 6. Claude queries Similarweb for current per-page traffic data, pulls the keyword-level traffic share for each cluster, and outputs a ranked execution list sorted by opportunity size relative to current page performance.
The output maps directly to sprint planning: Tier 1 optimization briefs, Tier 2 new content briefs, Tier 3 refresh briefs, and Tier 4 backlog. Each is backed by Similarweb traffic data, not editorial intuition. Setup instructions are in the Similarweb MCP keyword research automation guide.
Using AI to find keyword trends and search term popularity
Keyword trends and search term popularity are two of the most underused signals in keyword research, and two of the most reliably surfaced by AI assistants. A 79% zero-click rate on “keyword trends” signals that the majority of those searches are answered directly by a SERP feature or AI engine: a citation play, not a click play.
According to Similarweb keyword data from December 2025 through February 2026, “keyword trends” receives between 198 and 906 monthly searches in the US, depending on the month, with a keyword difficulty in the high 70s and a zero-click rate of approximately 60%.
“Search term popularity” shows a similar pattern: 145 to 265 monthly searches, keyword difficulty in the mid-70s, and a zero-click rate of around 47%. These are not high-volume queries. They are high-signal queries: the people searching them are practitioners making real decisions about what to target.
What keyword trends actually tell you
A keyword trend shows how search demand for a topic changes over time. A term growing at 20% month-over-month for three consecutive months is a materially different investment from a term with the same current volume but a flat trajectory. Traditional databases show you the current volume. The trend tells you where the volume is going.
AI tools accelerate trend detection in two ways. First, LLMs can reason about which topics are likely to gain traction (based on product launches, regulatory changes, or platform migrations) before that signal appears in any search volume database. Second, they can cluster semantically related terms to identify when multiple adjacent queries are rising simultaneously, which often indicates an emerging category rather than a single trending topic.
What search term popularity means in practice
Search term popularity is a relative measure of query frequency compared to the historical peak. It is useful for identifying seasonal and cyclical keyword behavior, and for understanding whether a currently high-volume term is near its ceiling or still growing.
The practical workflow: use an LLM to generate a list of terms you suspect are trending. Run each through Similarweb’s keyword trend view. Look for terms with rising month-over-month volume, particularly those the LLM flagged before the volume data confirmed the signal. For a systematic approach to identifying trending keywords, combining AI-driven ideation with Similarweb trend data yields faster, more comprehensive results than either approach alone.
Is AI keyword research accurate? How to validate AI keyword suggestions
AI keyword suggestions are ideas, not data. They require validation with real search volume and competition metrics before you build content around them. Used correctly, as an ideation, clustering, and classification layer followed by Similarweb validation, AI dramatically improves keyword research quality and speed. Used carelessly, it produces confident-sounding lists with no relationship to actual search demand.
The validation rule is simple: no LLM-generated keyword enters a content brief without a corresponding Similarweb data check. Volume, keyword difficulty, zero-click rate, and intent must all be confirmed. A keyword with zero volume and no rising trend gets cut unless it serves a specific zero-volume intent strategy with a clear conversion rationale.
There is a second, less discussed validation problem: LLMs can confidently generate keywords for concepts that do not yet exist as queries. The model is pattern-matching from training data, not querying a live keyword database. A term can appear frequently in training data without generating a single monthly search.
This is particularly common with emerging GEO and AI-specific terminology, where the vocabulary is actively being invented.
The fix is the same: validate everything. AI ideation without Similarweb validation is educated guessing. The combination is systematic.
Take your keyword research further with Similarweb
Using AI for keyword research is not a replacement for real keyword data. It is a layer that extends your coverage into demand that databases cannot see: zero-volume queries with real intent, emerging topics before they peak, and keyword clusters that would take hours to structure manually.
The ten methods in this guide cover the full keyword research workflow, from initial ideation through clustering, intent classification, competitor analysis, trend detection, and fan-out sub-query mapping. Use whichever subset fits your current brief, or run the full pipeline using the automated kv
and Similarweb MCP approach for maximum efficiency.
Use Similarweb’s MCP to validate AI-generated ideas, track trend trajectories, audit competitive gaps, and monitor keyword cluster performance over time.
FAQ
What is AI keyword research?
AI keyword research is the practice of using large language models and AI-powered tools to discover, cluster, classify, and prioritize keywords for SEO. Unlike traditional keyword databases that measure historical search demand, AI tools infer user intent, surface emerging topics before they appear in volume data, and identify zero-search-volume queries with real commercial intent. It is most effective when combined with Similarweb data validation.
What are the benefits of AI keyword research for marketing?
The primary benefits are speed of ideation and clustering, access to zero-search-volume queries that traditional databases cannot see, accurate intent classification at scale, earlier detection of emerging keyword trends, and coverage of the questions users are asking AI engines directly. For GEO-oriented strategies, AI keyword research also maps the fan-out sub-queries LLMs decompose your topic into, which determines citation eligibility in AI-generated answers.
How do I find keyword trends using AI?
Ask an LLM to identify emerging topics in your niche, then cross-reference those suggestions with Similarweb’s keyword trend view, which shows month-over-month and year-over-year volume changes per query. Terms the model flags as emerging that are simultaneously showing rising Similarweb volume data are your highest-priority content investments. The combination of AI pattern recognition and validated Similarweb trend data is faster and more reliable than either approach alone.
What is search term popularity, and how do I measure it?
Search term popularity is a relative measure of how frequently a query is performed compared to its historical peak. It is useful for identifying seasonal and cyclical keyword behavior and for understanding whether a high-volume term is still growing or approaching its ceiling. Measure it in Similarweb’s keyword overview by looking at year-over-year volume trends alongside current monthly search data.
Can AI help with keyword gap analysis?
Yes. Use an LLM to identify topics your competitors appear to be covering systematically that your content is missing. Then, validate those gaps in Similarweb using the keyword gap analysis feature to confirm which gaps have search volume that your existing content is not capturing. This prioritizes gaps based on actual demand rather than on competitive impression alone.
Is AI keyword research accurate? How do I validate AI keyword suggestions?
AI keyword suggestions are ideas generated through pattern recognition, not live search data queries. They require validation with real volume, keyword difficulty, and zero-click rate data before any content investment. No LLM-generated keyword should enter a content brief without a corresponding Similarweb data check. The combination of AI ideation and Similarweb validation is accurate and efficient; AI ideation alone is not.
How does AI keyword research work for AI search engines like ChatGPT and Perplexity?
For AI search optimization, keyword research extends beyond volume and difficulty into query fan-out mapping. When an LLM receives a user question, it decomposes it into multiple sub-queries and retrieves content for each independently. AI keyword research for AI search engines means identifying those sub-queries using the FAN methodology, validating their volume and zero-click rate in Similarweb, and structuring content so each section is independently citable.
What is keyword clustering and how does AI make it faster?
Keyword clustering is the practice of grouping related search terms by shared topic and user intent so they can be targeted together on a single page or within a content cluster. Doing it manually on a large keyword list takes hours. An LLM groups the same list by semantic meaning in seconds, outputting named clusters with annotated intent. Validate each cluster’s aggregate volume and difficulty in Similarweb before committing to a content plan.
How does AI improve search intent classification for keyword research?
AI improves search intent classification by analyzing the semantic meaning of a query rather than matching patterns against keyword signals. Traditional rule-based classification misses nuance: a query like “best project management setup” can be informational or commercial depending on context. Feed your keyword list to an LLM for intent classification, then cross-reference against Similarweb’s intent distribution data per keyword to catch mismatches before they become content strategy errors.
How long does AI keyword research take compared to doing it manually?
For a single topic cluster, manual keyword research covering ideation, clustering, intent classification, competitor analysis, and brief population takes roughly 3 to 5 hours. Using an LLM for ideation and clustering validated in Similarweb reduces that to under an hour for most briefs. The Similarweb MCP pipeline applied to the full FAN methodology completes the same process in under 20 minutes. Time savings scale significantly when running research across multiple topic clusters simultaneously.

Related Posts



What Is AI Share of Voice? The Brand Mention Share Metric You’re Probably Missing




Track Gen-AI And Organic KPI's On The #1 SEO Platform
Give it a try or talk to our marketing team - it’s free!